
Al aprender sobre el ANOVA de una vía, sabemos que el ANOVA se utiliza para identificar la diferencia de medias entre más de dos grupos. Un ANOVA de una vía se utiliza cuando tenemos una variable de agrupación y un resultado continuo. Pero, ¿qué debemos hacer si tenemos dos variables de agrupación? Como probablemente habrá adivinado, podemos realizar un ANOVA de dos vías. Debido a que esta situación es bastante común, he creado la siguiente página para proporcionar una guía paso a paso para el cálculo de un ANOVA de dos vías en Excel. Como siempre, si tiene alguna pregunta, envíeme un correo electrónico a MHoward@SouthAlabama.edu.
Como se ha mencionado, un ANOVA se utiliza para identificar la diferencia de medias entre más de dos grupos, y un ANOVA de dos vías se utiliza para identificar la diferencia de medias entre más de dos grupos cuando se tienen dos variables de agrupación y un resultado continuo. Así, un ANOVA de dos factores se utiliza para responder a preguntas similares a las siguientes:
- ¿Cuál es la diferencia media de las notas de los exámenes entre los alumnos zurdos y diestros, los alumnos de las clases del Dr. Howard y del Dr. Smith, y las combinaciones de estos grupos?
- ¿Cuál es la diferencia media en la producción total de las fábricas definidas tanto por ubicación como por industria?
- ¿Cuál es la diferencia media en el rendimiento de cuatro programas de formación diferentes, cada uno realizado en cuatro lugares distintos, y la combinación de programa de formación y lugar?
Además, al probar estos efectos, un ANOVA de dos vías puede determinar si la Variable 1 tiene un efecto, si la Variable 2 tiene un efecto y si hay una interacción entre la Variable 1 y la Variable 2. Una interacción indica que el efecto de la Variable 1 depende de la Variable 2 y que el efecto de la Variable 2 depende de la Variable 1. Una interacción indica que el efecto de la Variable 1 depende de la Variable 2 y que el efecto de la Variable 2 depende de la Variable 1. Una forma de verlo es: La Variable 1 puede tener un efecto, la Variable 2 puede tener un efecto, pero una interacción se produce cuando ocurre algo especial cuando la Variable 1 y la Variable 2 se estudian juntas. Por ejemplo, los efectos pueden ser multiplicativos cuando se estudian juntas.
Ahora que sabemos para qué se utiliza un ANOVA de dos vías, podemos calcular un ANOVA de dos vías en Excel. Para empezar, abra sus datos en Excel. Si no tiene un conjunto de datos, descargue el conjunto de datos de ejemplo aquí. En el conjunto de datos de ejemplo, simplemente estamos comparando las medias de dos variables de agrupación diferentes, cada una con tres grupos diferentes, en un único resultado continuo. Las variables son la Variable 1 (Grupo A, B y C) y la Variable 2 (Grupos 1, 2 y 3). Puede imaginar que los grupos y el resultado son cualquier cosa que quiera.
Antes de seguir, debo señalar que Excel es bastante malo en el cálculo de un ANOVA de dos vías, por lo que recomiendo el uso de Jamovi, SPSS, R, o Python en su lugar. Sin embargo, si necesita utilizar Excel, puede calcular un resultado para usted.
Una vez hecho esto, el conjunto de datos debería parecerse a la siguiente imagen.
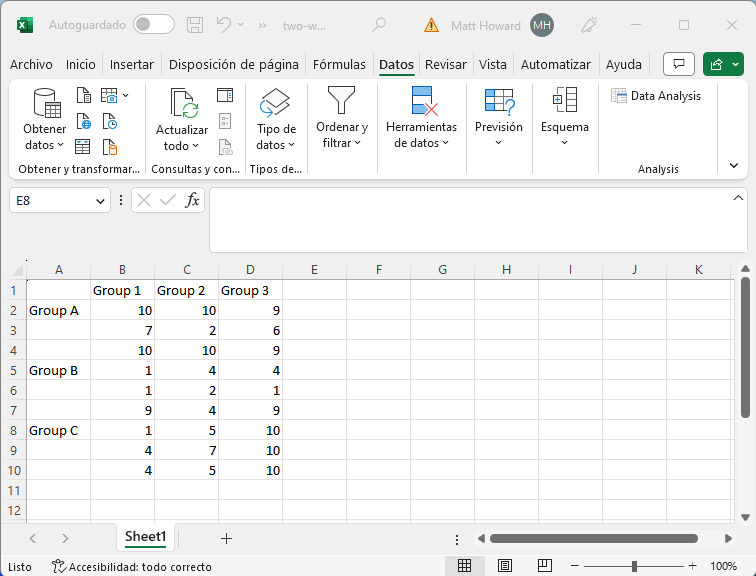
Como la mayoría de los otros análisis, debemos empezar por ir a la pestaña Datos y hacer clic en data Analysis. Si no tiene el botón Data Analysis, lea mi guía sobre cómo activar el Data Analysis en Excel.
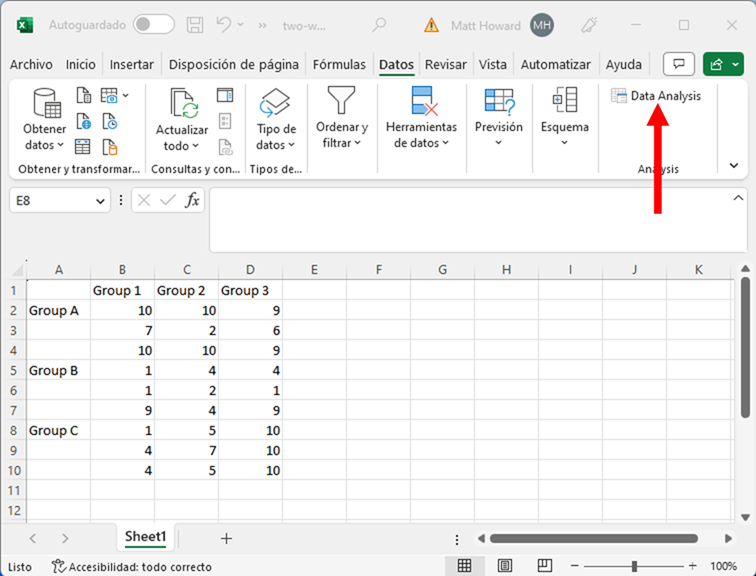
Haga clic en “Anova: Two-Factor With Replication” y, después, en “OK”.
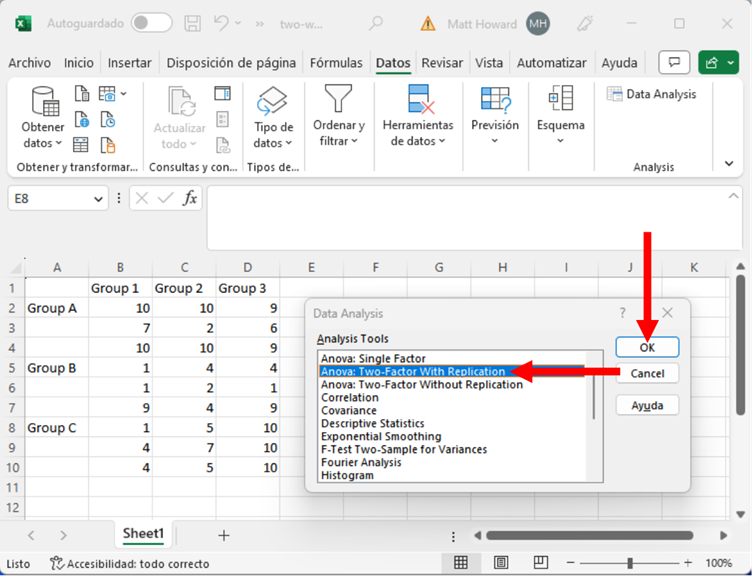
Haga clic en el botón resaltado a abajo, que le indica a Excel dónde se encuentran sus datos.
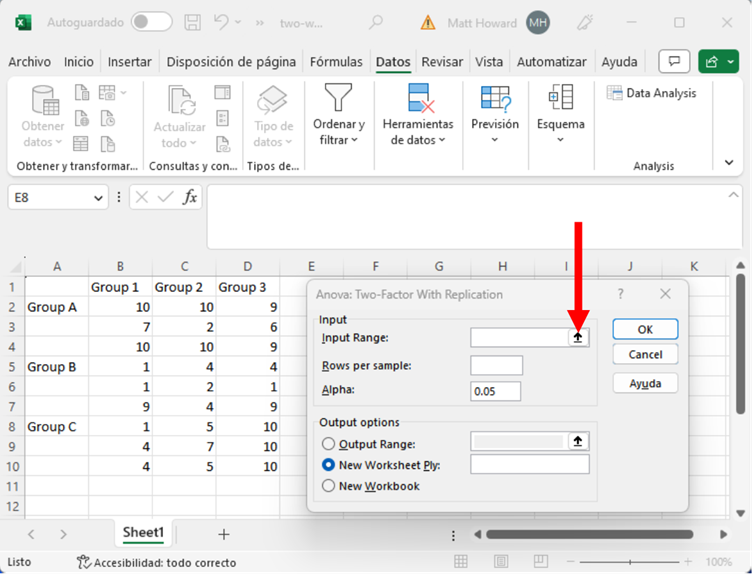
Resalte todos sus datos Y sus etiquetas. Luego pulse el otro botón resaltado abajo.

Ahora, tenemos que decirle a Excel cuántos participantes hay en nuestros grupos. Como puede ver arriba, hay dos variables de agrupación, cada una con tres grupos. Esto hace un total de nueve grupos: 1A, 2A, 3A, 1B, 2B, 3B, 1C, 2C y 3C. En cada uno de estos grupos, tenemos tres números. Por ejemplo, el grupo 1A tiene valores de 10, 7 y 10. Esto significa que tenemos tres participantes por grupo. Por lo tanto, si está utilizando el conjunto de datos de ejemplo, introduzca “3” en la casilla resaltada más abajo.
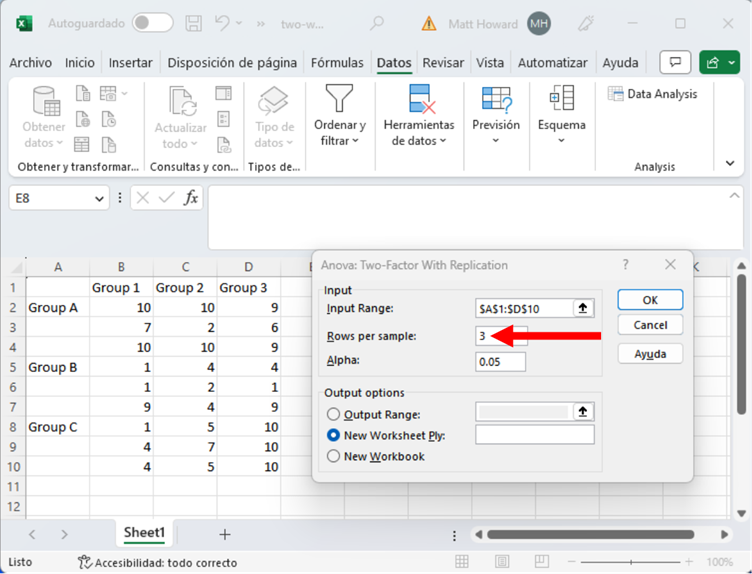
Ahora su pantalla debería parecerse a la siguiente. Pulse “OK”.

El resultado debería ser el siguiente:
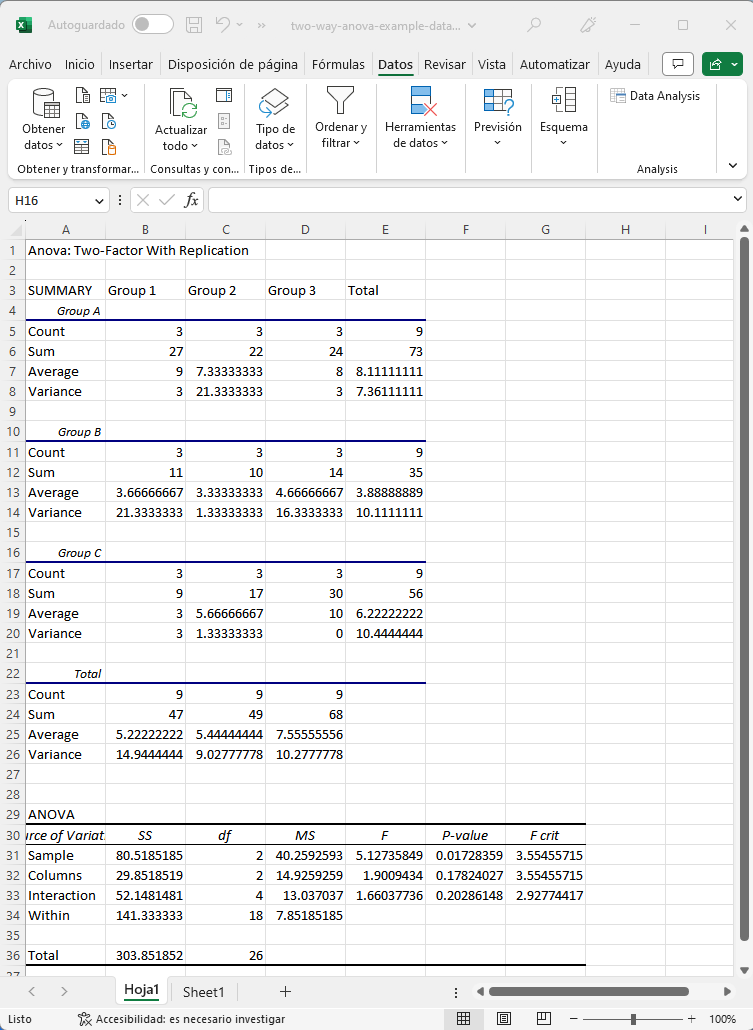
¡Vaya! ¡Eso es un montón de salidas! No se preocupe, le guiaremos paso a paso.
En primer lugar, determinaremos si la variable que definió nuestras filas tiene un efecto estadísticamente significativo. En el conjunto de datos del ejemplo, se trata de la Variable 1 (Grupo A, B y C). Para determinar si es estadísticamente significativa, veamos primero el estadístico F, que es nuestro estadístico de prueba.
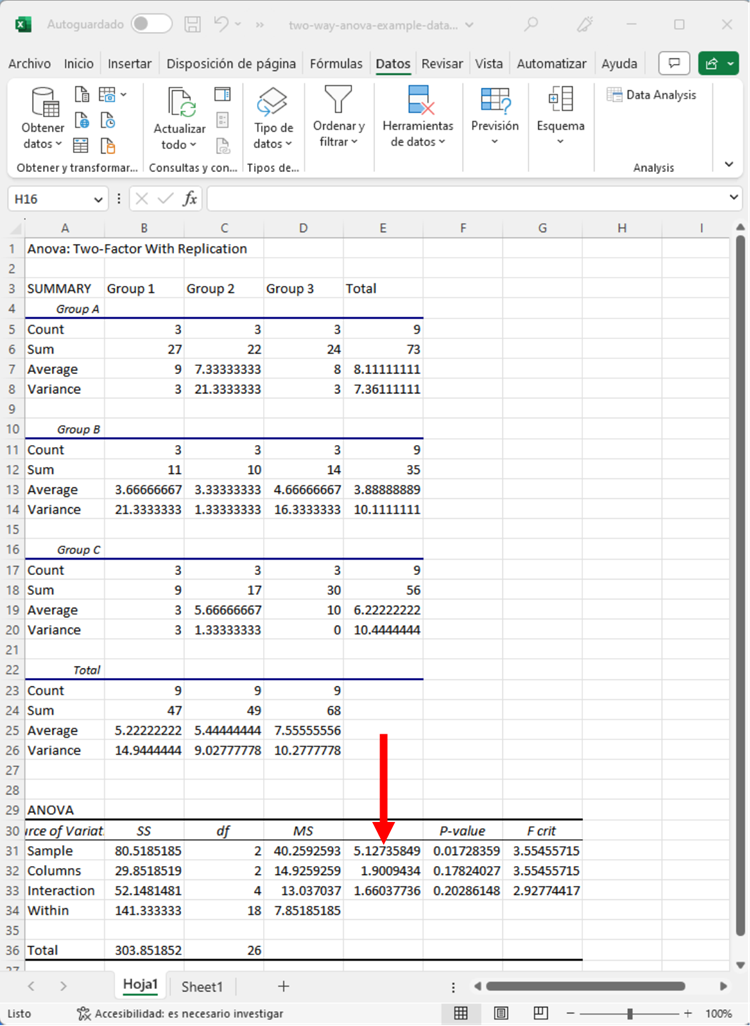
El estadístico F de la Variable 1 fue de 5.127. Aunque nos gustaría comunicarlo, el estadístico F no nos dice mucho por sí solo. Por tanto, deberíamos fijarnos en el valor p.
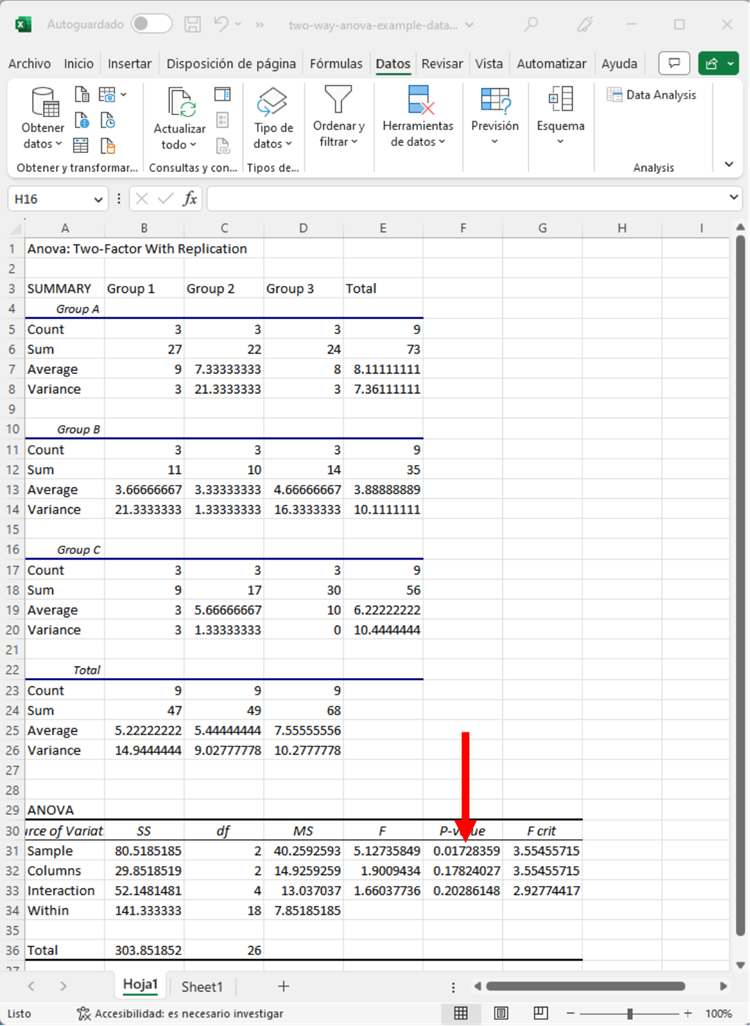
El valor p fue 0.017. Como es inferior a 0.05, consideramos que el efecto de la Variable 1 es estadísticamente significativo. Por lo tanto, hay una diferencia significativa entre los Grupos A, B y C.
Ahora, veamos los resultados de la Variable 2 (Grupos 1, 2 y 3).
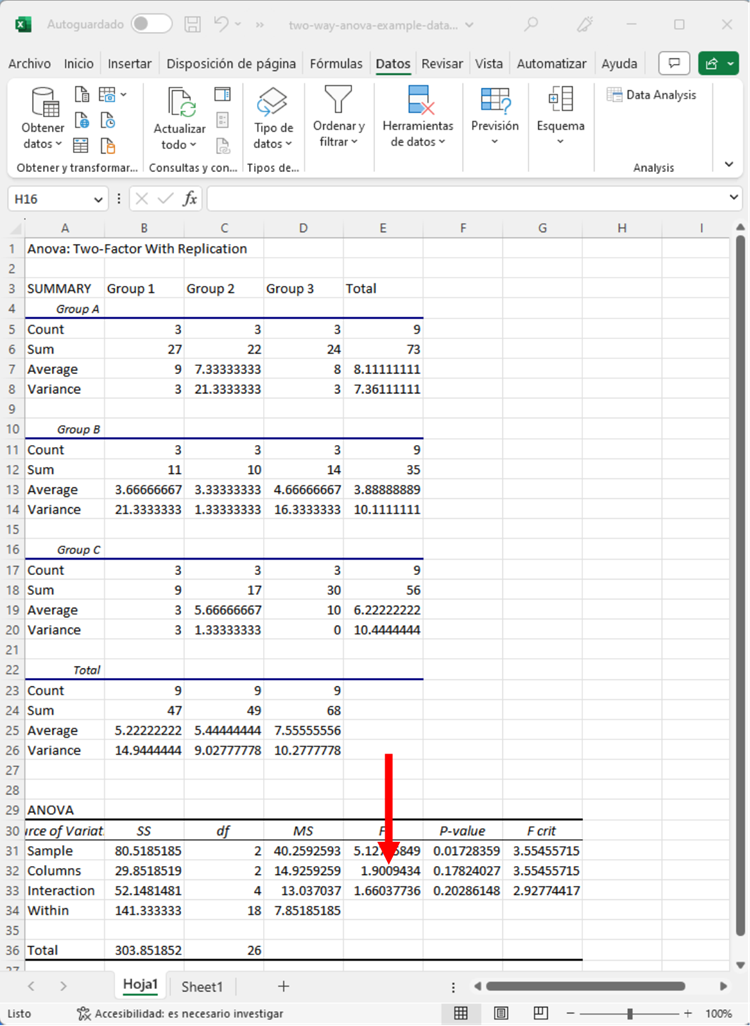
El estadístico F es 1.901. De nuevo, debemos informar de este valor, pero también fijarnos en el valor p para determinar cómo interpretar nuestros resultados.
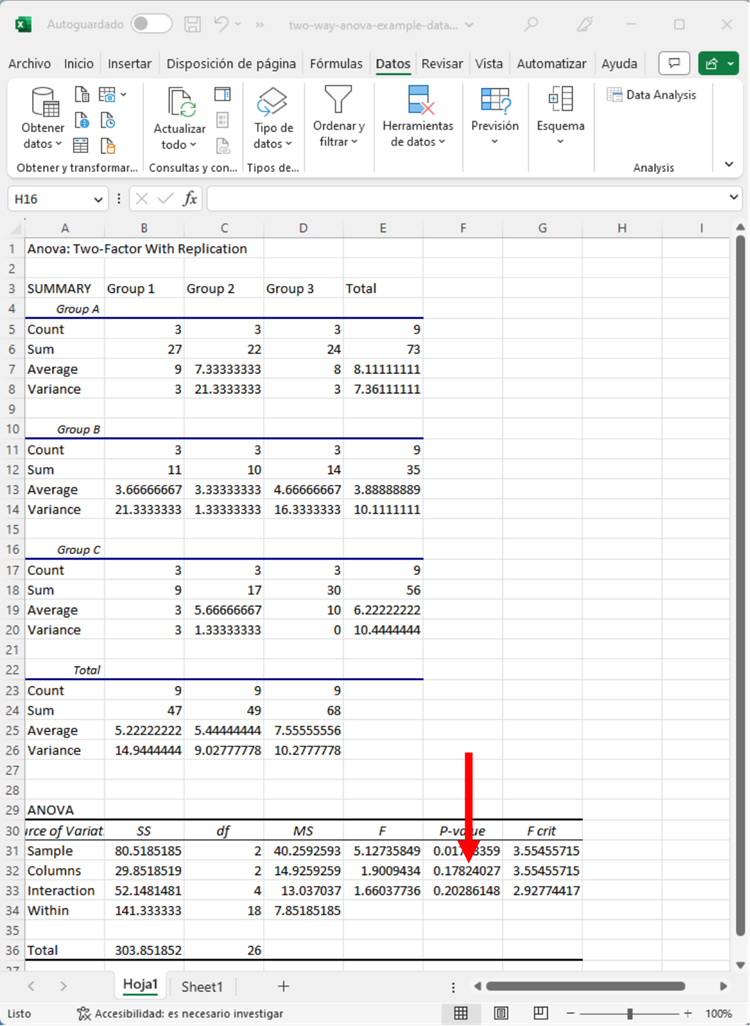
El valor p es 0.178. Como es superior a 0.05, nuestro resultado no es estadísticamente significativo. Por lo tanto, podríamos decir que la Variable 2 no tiene un efecto significativo, y no hay una diferencia notable entre los Grupos 1, 2 y 3.
Por último, veamos el término de interacción.

El estadístico F es 1.660. Informemos de esto, pero veamos también el valor p.
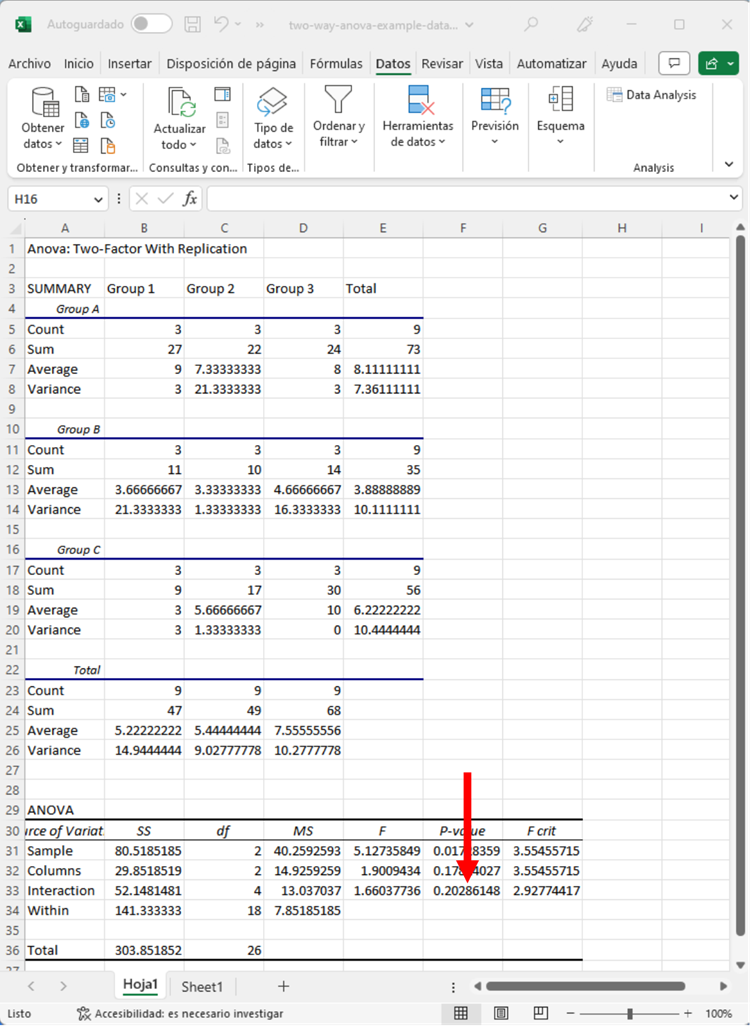
El valor p es 0.203. Este resultado no es estadísticamente significativo, y por lo tanto diríamos que no hay interacción significativa entre la Variable 1 y la Variable 2.
En conjunto, sabemos que hay un efecto significativo para la Variable 1, pero no hubo un efecto significativo para la Variable 2 o la interacción. Como la Variable 1 fue significativa, sabemos que hay algún tipo de diferencia entre los Grupos A, B y C. Pero, ¿en qué se diferencian?
Si utilizáramos un programa más avanzado, como Jamovi, SPSS, R, or Python, podríamos realizar pruebas post hoc o comparaciones planificadas. Desafortunadamente, Excel no tiene esta característica fácilmente implementada. Por lo tanto, nos limitaremos a observar las medias de los grupos.
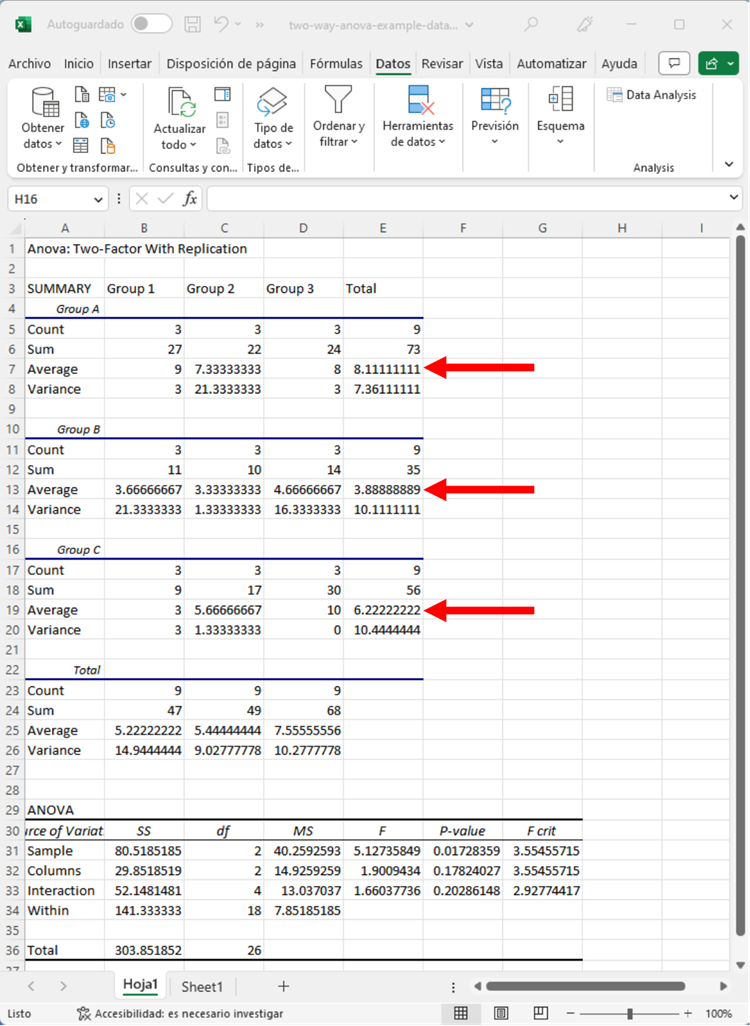
Las medias resaltadas corresponden a los Grupos A, B y C. Al observar las medias, podemos ver que el Grupo A tiene el valor más alto, seguido del Grupo C y del Grupo B. Aunque no sabemos si estas comparaciones específicas son significativas, podemos hacernos una idea general de cómo difieren los grupos.
Pero, ¿y si la Variable 2 fuera estadísticamente significativa? Bueno, podemos fijarnos en los valores resaltados abajo.
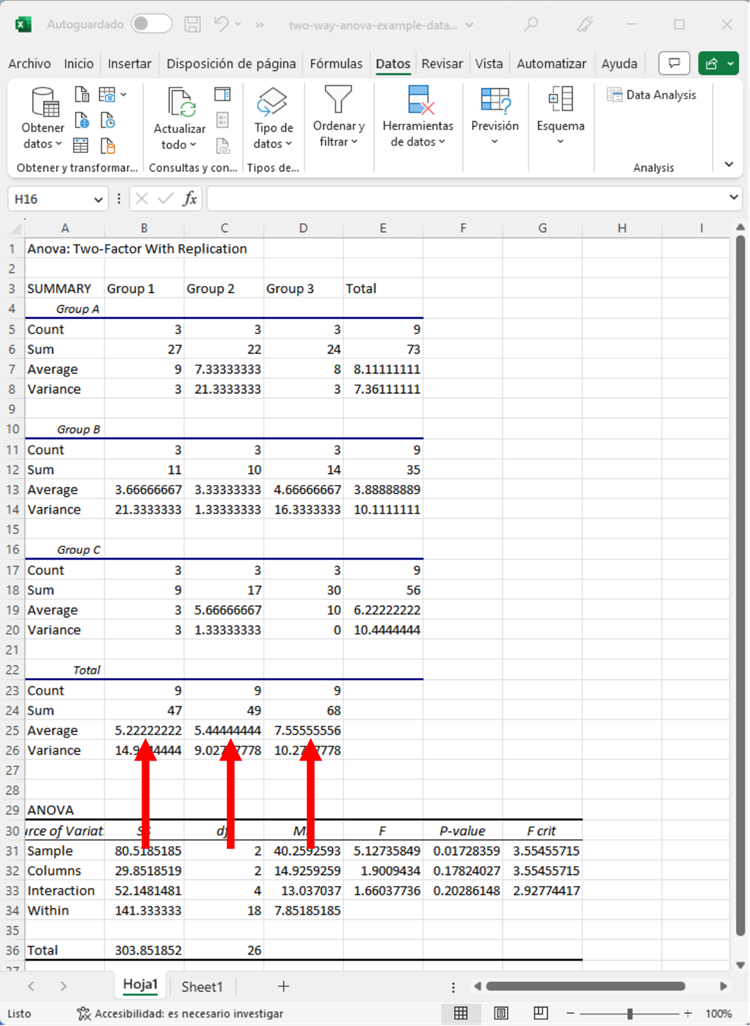
A partir de estas medias, podemos ver que el Grupo 3 tenía una media ligeramente superior a la de los Grupos 1 y 2; sin embargo, como la Variable 2 no tenía un efecto significativo, estas diferencias no son estadísticamente significativas.
Por último, si tuviéramos un efecto de interacción significativo, tendríamos que observar las medias de todos los grupos. Están resaltadas en la siguiente imagen.
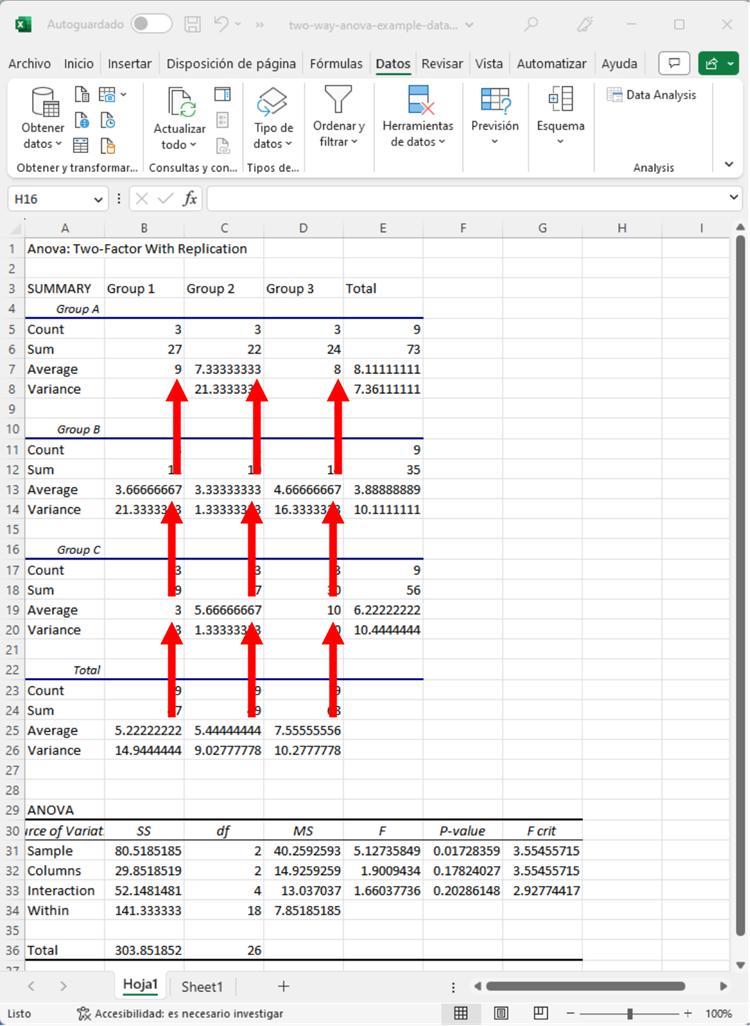
A partir de esta imagen, podemos ver que el Grupo C3 tenía un valor de 10, el Grupo A1 tenía un valor de 9, y los grupos descendieron a partir de ahí. Como no hubo un efecto de interacción significativo, estas comparaciones de grupos individuales no son tan significativas.
¡Vaya! Ha sido mucho, pero ya hemos terminado. Si tiene alguna pregunta o comentario, envíeme un correo electrónico a MHoward@SouthAlabama.edu.
