
Regression is a powerful tool. Fortunately, regressions can be calculated easily in Python. This page is a brief lesson on how to calculate a regression in Python. As always, if you have any questions, please email me at MHoward@SouthAlabama.edu!
The typical type of regression is a linear regression, which identifies a linear relationship between predictor(s) and an outcome. In other words, a regression can tell you the relatedness of one or many predictors with a single outcome. Regression also tests each of these relationships while controlling for the other predictors, and it can be used to answer the following questions and similar others:
- What is the relationship of job satisfaction and leader ability in predicting employee job satisfaction?
- What is the relationship of hours studied and test grades?
- What is the relationship between NBA player height, weight, wingspan and the number of points scored per game?
Of course, there is more nuance to regression, but we will keep it simple. To answer these questions, we can use Python to calculate a regression equation. If you don’t have a dataset, you can download the example dataset here.
First, you need to install two modules. We are going to be using the pingouin and pandas modules. If you don’t know how to install modules, please refer to my page on installing Python modules. Second, you need to open your data into Python. If you do not know how to do this, please refer to my page on opening .csv values into Python. Your syntax should now look something like this to start:

Let’s conduct a regression with Var2 and Var3 predicting Var 1. We can now type our command syntax. We want to start with our command, which is pg.linear_regression( . Then, we want to enter our predictor variables by typing: [MyData[‘Var2’], MyData[‘Var3’]], . This should be followed by our outcome variable with a closed parenthesis, like so: MyData[‘Var1’]) . Once we have all of that, we can press enter:

Did you? If so, great! Let’s look at these results. In the coefficients section, we get an estimate for each predictor (beta), a standard error, and. . .oh! It seems that a lot of columns got cut off. How can we fix this?
We can assign our regression results to a variable. To do this, we can start by coping the syntax that we just entered. Don’t worry! You don’t need to retype it. Instead, you can click your mouse on the syntax that you just typed and then hit the enter key. Once you do that, your syntax should automatically copy. Now move your cursor to the beginning of the syntax and type: lm = . This will assign your regression results to the variable, lm. Once you have it, press enter.

To better see our regression results, let’s tell Python to show us lm with all values rounded to two decimal places. To do this, type: lm.round(2) .
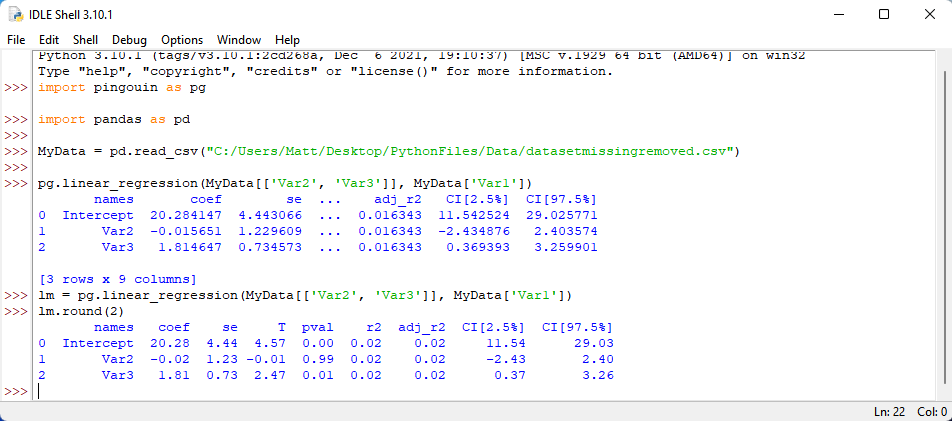
Much better! In the coefficients section, we get an estimate for each predictor (beta), a standard error, a t-statistic, a p-value, and so on. From these results, we can see that Var2 was not a significant predictor of Var1, but Var3 was a significant predictor of Var1. Interesting! We can also see our overall model results, such as the multiple R^2, which may be of interest to some readers.
From this example, you should be able to run a regression on your own in Python. You can also use the example dataset to create different regression equations. If you have any questions or comments while doing so, feel free to email me at MHoward@SouthAlabama.edu.
