
Once you have completed the first step of using Python, installing the program, you need to figure out the second step, installing modules in Python. Once you have completed the second step, you need to figure out the third step, opening your data in Python. There are dozens of ways to open your data in Python, but the current page is a brief guide on likely the easiest way: opening your data as a .csv file in IDLE. If you have any questions or comments about the current guide, please email me at MHoward@SouthAlabama.edu.
As mentioned above, the current guide provides instructions on opening a .csv file in Python. If you typically handle your data in Excel, however, your data is probably in a .xls or .xlsx format. Fortunately, changing your data from .xls or .xlsx format to .csv is extremely easy to do (if you have Excel!), and I covered this in my opening .csv files in R guide. Click here if you need to figure out how to change your .xls or .xlsx files to .csv.
Once you have done that, you need to open IDLE. IDLE enables us to write Python code and run it at the same time, rather than having to write all our code and then run it. This enables us to immediately determine if we made a mistake with a line of code, which makes the learning process a lot quicker. To open IDLE, first go to your search tool on the task bar (seen below).

Click on the search box.

Type in “idle”.

Now click on IDLE. As you see in my image below, I had two types of IDLE appear. This is because I have two different version of Python installed on my computer. Make sure that you are opening the version that you actually want to open. For me, this was Python 3.10, which is why I click on the second one below.

IDLE should open and appear like the image below.

First, we want to import the module pandas, and we want to refer to it as pd. If you have not installed the pandas module, first follow my guide on installing modules in Python. It goes over how to install pandas, and you can click here to access it. Once you have pandas installed, we want to type into IDLE “import pandas as pd”.

Once you do so, then press enter.
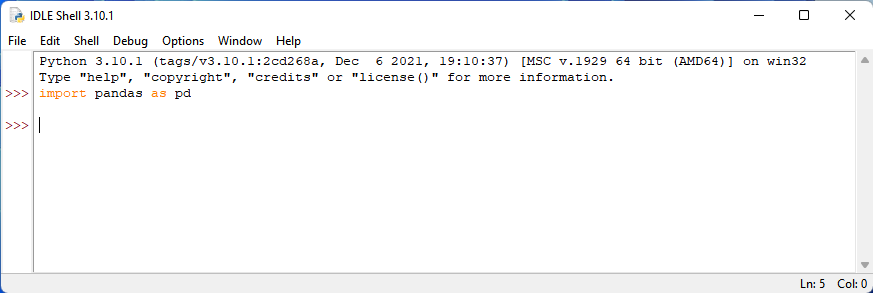
It will seem like nothing has happened. That is okay! Let’s just continue with our code.
We now need to create a term for our dataset to be assigned to, and we need to type the syntax to open our dataset. To do so, let’s start by typing “data = pd.read_csv(“. Because we started with “data =”, our dataset will be called “data” once we finish the code. Of course, you can name it anything else if you want to.

We then want to enter the file path of our dataset. The easiest way to do so is to open the folder containing our dataset, right click on it, and click on “Copy as path”. This will copy the file path.

We should go back to our code and first type a single quotation mark. Then we should paste the text that we copied in the step above by pressing CTRL+V. Afterwards, we want to close our quotation mark. Your code should appear similar to the text below, but your file path will of course differ from mine.

Before we can do anything else, we need to change all the backslashes in our file path to forward slashes, seen below.

Let’s go ahead and close that parenthesis.

And hit enter twice.

It will seem like nothing happened again. That is okay, as long as you didn’t receive an error. To verify that our dataset was assigned to the term, “data”, we can now type in the term “data”. Go ahead and do that.
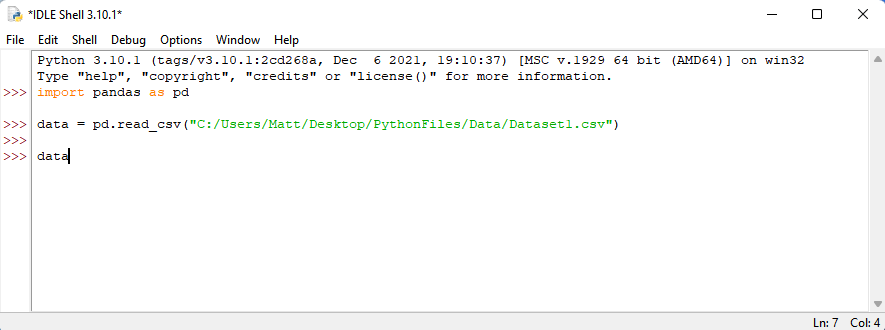
Press enter.

And we see our dataset. Great!
That is all for the most basic way of opening our data in Python. Now we can move on to conducting statistical analyses – exciting stuff! If you have any questions or comments, please email me at MHoward@SouthAlabama.edu.
