
La prueba chi-cuadrado de independencia, también llamada prueba chi-cuadrado de dos variables, es tal vez incluso más popular que la prueba chi-cuadrado de una variable. Al igual que la prueba de chi-cuadrado de una variable, también es una de las pocas estadísticas básicas que el complemento “Data Analysis” de Excel no realiza, y es difícil de calcular sin SPSS, R o un programa estadístico diferente. He creado esta guía sobre el cálculo de la prueba chi-cuadrado de independencia en Excel para ayudarte a resolver este problema. Espero que a alguien le resulte útil. Como siempre, envíame un correo electrónico a MHoward@SouthAlabama.edu si tienes alguna duda sobre la prueba chi-cuadrado de independencia.
Como probablemente ya sepas, una prueba chi-cuadrado de una variable determina si existe un número igual (o desigual) de observaciones en las categorías de una única variable de agrupación. Si aún no conoces las pruebas de chi cuadrado de una variable o cómo realizarlas en Excel, te recomiendo que le eches un vistazo a mi guía sobre el tema (haz clic aquí).
El objetivo de una prueba de chi-cuadrado de independencia es un poco diferente. Determina si la distribución de las observaciones entre los grupos de una variable categórica (también conocida como variable de agrupación) depende de otra variable categórica. Veamos algunos ejemplos para aclarar esta idea.
Imagínate que tienes tres personas fabricando juguetes (Sue, Joe y Bob), y que registras el número de defectos en los juguetes fabricados (con defecto y sin defecto). En este ejemplo, tienes dos variables de agrupación: persona y defecto. El grupo de personas tiene tres categorías (Sue, Joe y Bob) y el grupo de defectos tiene dos categorías (defecto y sin defecto). Podríamos realizar una prueba chi-cuadrado de independencia para determinar si los defectos se distribuyen uniformemente entre las tres personas, o si hay una distribución desigual de los defectos y una persona puede estar produciendo significativamente más o menos que las otras. En este caso, estaríamos probando si la distribución de las observaciones para nuestra variable de defecto depende de nuestra variable de persona.
He aquí otro ejemplo: Imaginemos que tenemos cuatro profesores (Dr. Howard, Dr. Smith, Dr. Kim y Dr. Chow) y registramos el número de alumnos que no aprueban en esas clases. De nuevo, tenemos dos variables de agrupación: profesor y estado de aprobado/reprobado. El grupo de profesores tiene cuatro categorías (Dr. Howard, Dr. Smith, Dr. Kim y Dr. Chow) y el grupo de aprobados/reprobados tiene dos categorías (aprobados y reprobados). Podríamos realizar una prueba chi-cuadrado de independencia para determinar si los alumnos reprobados se distribuyen uniformemente entre los cuatro profesores, o si existe una distribución desigual de los alumnos reprobados y algunos profesores pueden estar produciendo significativamente más o menos que los demás. En este caso, estaríamos probando si la distribución de las observaciones para nuestra variable aprobado/reprobado depende de nuestra variable persona.
Dos últimas observaciones sobre la prueba chi-cuadrado de independencia antes de aprender a calcularla en Excel: En primer lugar, cuando me la enseñaron, me enseñaron que prueba si existe una interacción entre dos variables categóricas con respecto a la distribución de sus observaciones. Si te ayuda pensarlo de esta manera, hazlo. En segundo lugar, la prueba chi-cuadrado parece similar a una prueba t. Una forma fácil de recordar la diferencia es que la prueba chi-cuadrado utiliza una variable categórica como resultado, mientras que la prueba t utiliza una variable continua como resultado. También puede decirse que la prueba chi-cuadrado utiliza el número de observaciones como resultado, mientras que la prueba t utiliza una variable continua como resultado.
Ahora que sabemos para qué se utiliza una prueba chi-cuadrado de independencia, podemos calcularla en Excel. Para empezar, abre tu conjunto de datos en Excel. Haz clic aquí para ver el conjunto de datos que utilizaré en este ejemplo. Incluye el sexo y el color del pelo de 60 estudiantes seleccionados aleatoriamente, y comprobaremos si existe una asociación entre el sexo y el color del pelo con respecto al número de observaciones para sus respectivas categorías. En otras palabras, ¿el número de hombres o mujeres depende del color del pelo y/o el número de estudiantes rubios o castaños depende del sexo?
Los datos deben verse como sigue:
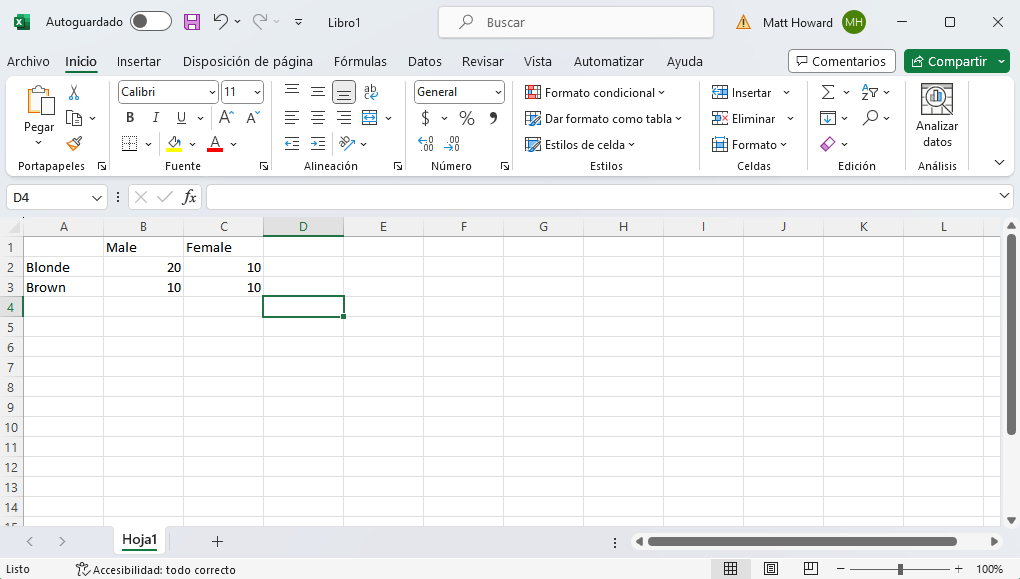
En primer lugar, debes sumar las filas y columnas con la función =SUMA(). Empecemos por la fila superior. Para sumar esta fila, selecciona la celda situada junto al final de la fila, como se ve abajo. Luego escribe “=Suma(“, selecciona las dos celdas que quieras sumar y escribe “)”. No incluyas las comillas en ninguna de estas instrucciones. Esto sumará la fila por ti, como se ve a continuación:
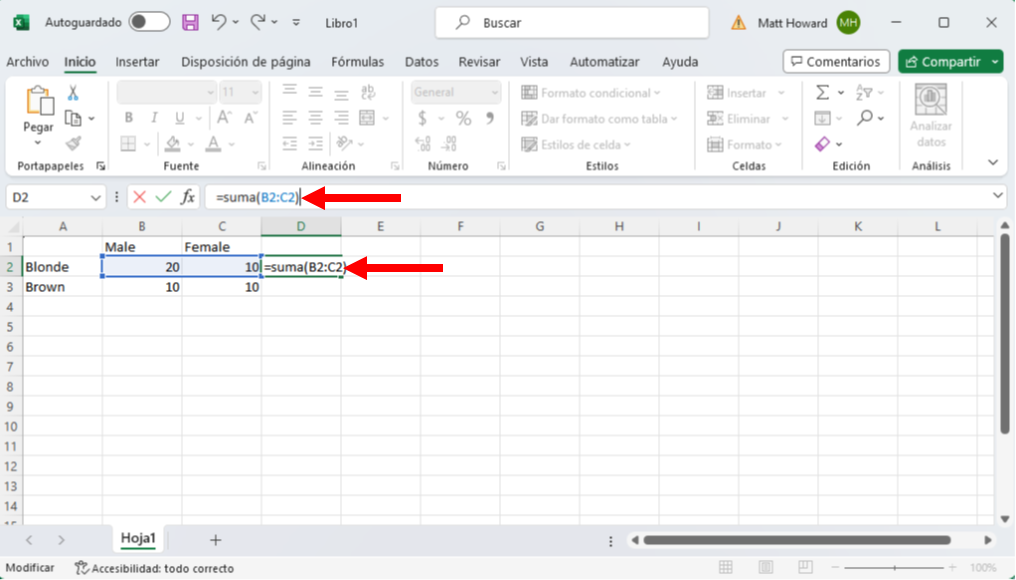
Queremos repetir este proceso para la otra fila y las dos columnas. Basta con utilizar de nuevo la función =SUMA() utilizando las mismas celdas que abajo.
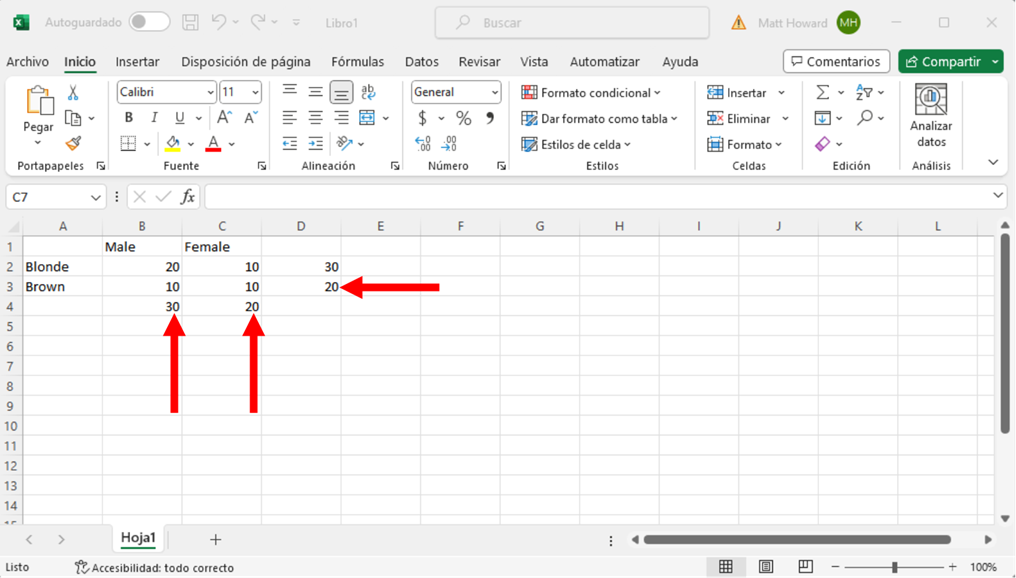
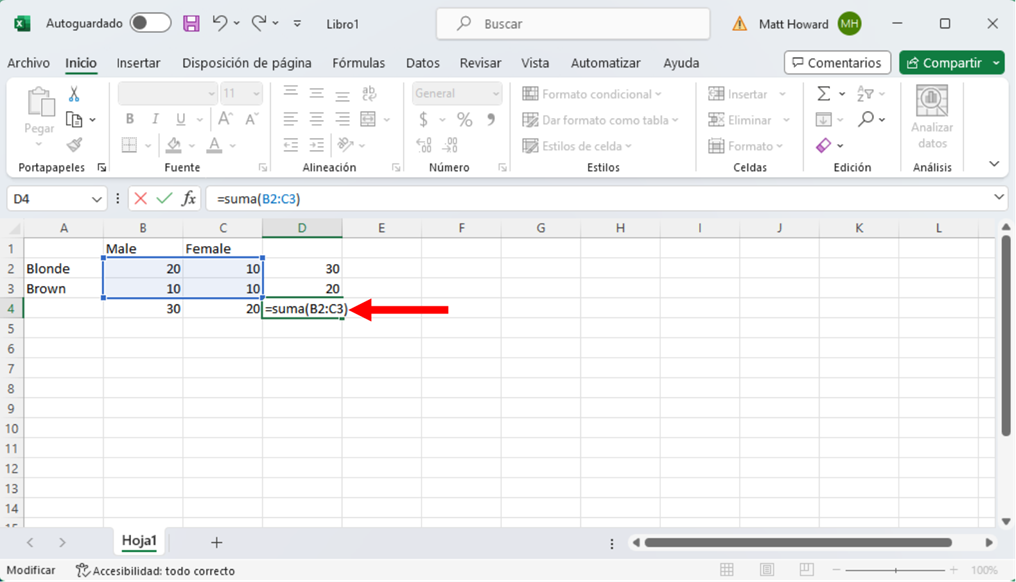
Luego queremos obtener el total general de todas las observaciones. Selecciona la celda vacía de abajo a la derecha. Después, utiliza la función =SUMA() y selecciona las cuatro celdas originales. Esto nos dará el total general de todas las observaciones, como se ve a continuación.
Ahora tenemos que calcular los valores esperados de cada celda. Para ello, multiplicamos la suma de la fila de la celda por la suma de la columna de la celda y, luego, dividimos por el número total de observaciones. Para hacerlo para la celda superior izquierda, primero seleccionamos una celda vacía, como la que se resalta a continuación. Después, escribimos “=(“, seleccionamos la suma de la fila superior, escribimos “*”, seleccionamos la suma de la columna izquierda, escribimos “)/”, seleccionamos el total general de observaciones y pulsamos intro. Esto nos dará: =(B4*D2)/D4, como se ve en la imagen de abajo.
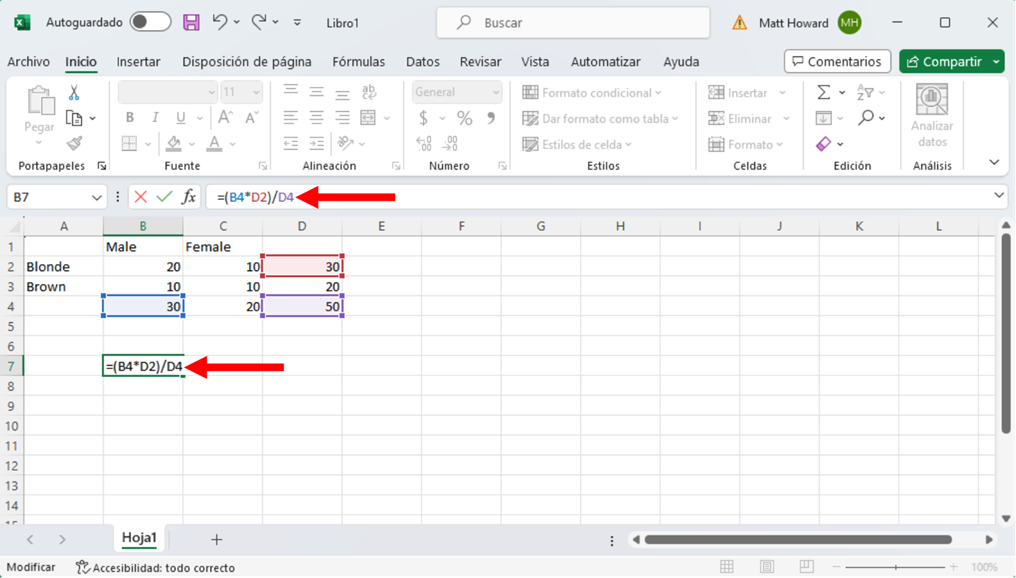
Queremos hacer lo mismo para las otras celdas. Te guiaré a través de cada una, ya que esta parte es un poco complicada.
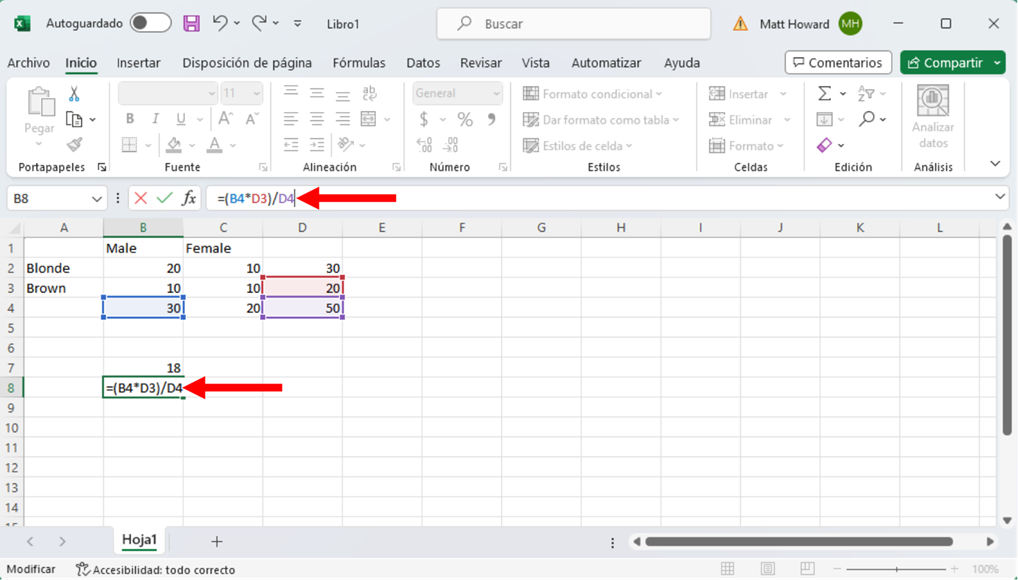
Para obtener el valor esperado para la celda inferior izquierda, multiplicamos la suma de la fila inferior por la suma de la columna izquierda y dividimos por el total general de observaciones. Puedes ver esto en la imagen de abajo, incluyendo la fórmula que utilizarás.
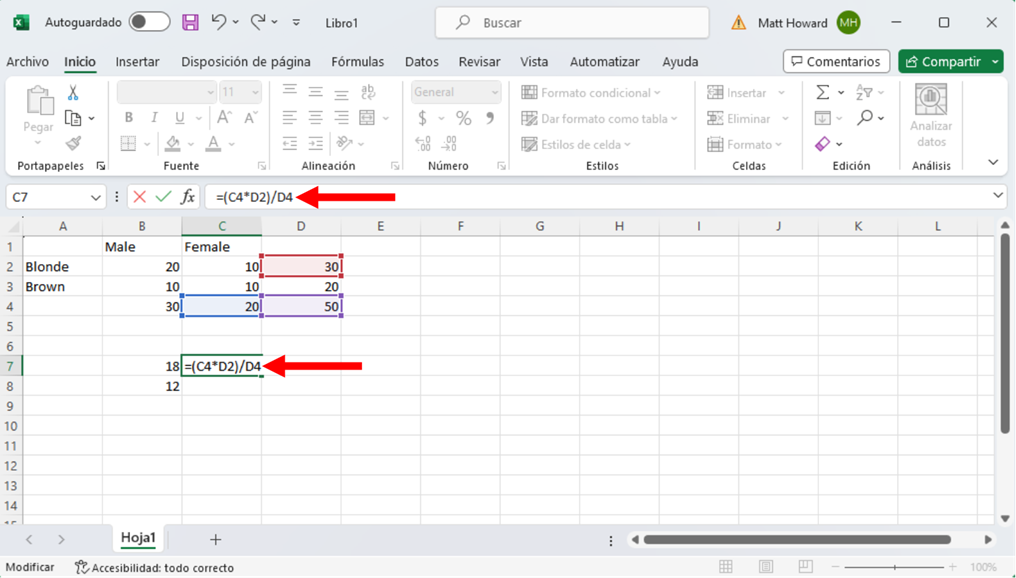
La imagen siguiente incluye la fórmula para la celda superior derecha.
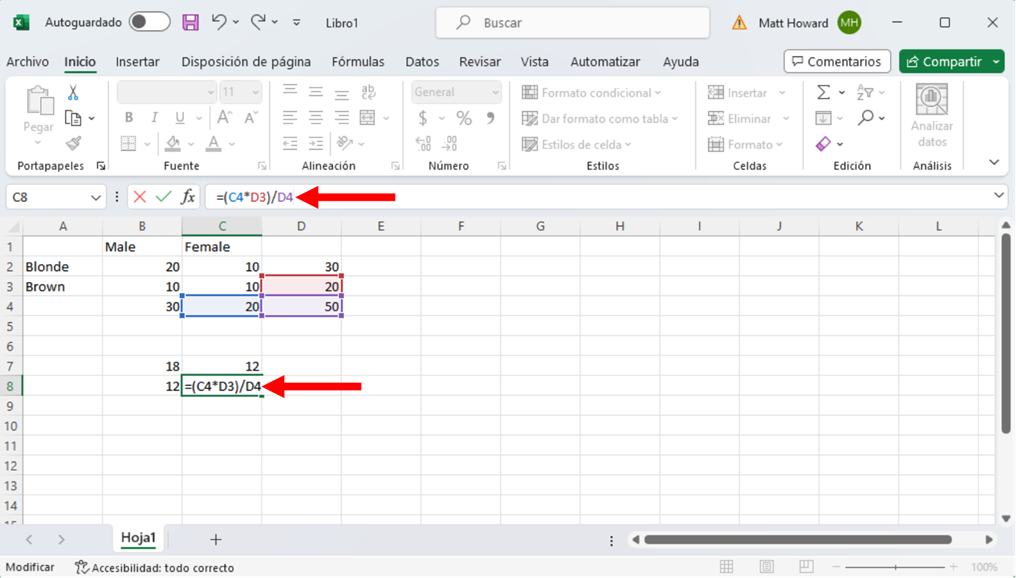
Y la imagen de abajo incluye la fórmula para la celda inferior derecha.
Ahora vamos a etiquetar estas cuatro nuevas celdas. Yo utilicé la etiqueta, “Expected Values”(Valores Esperados).
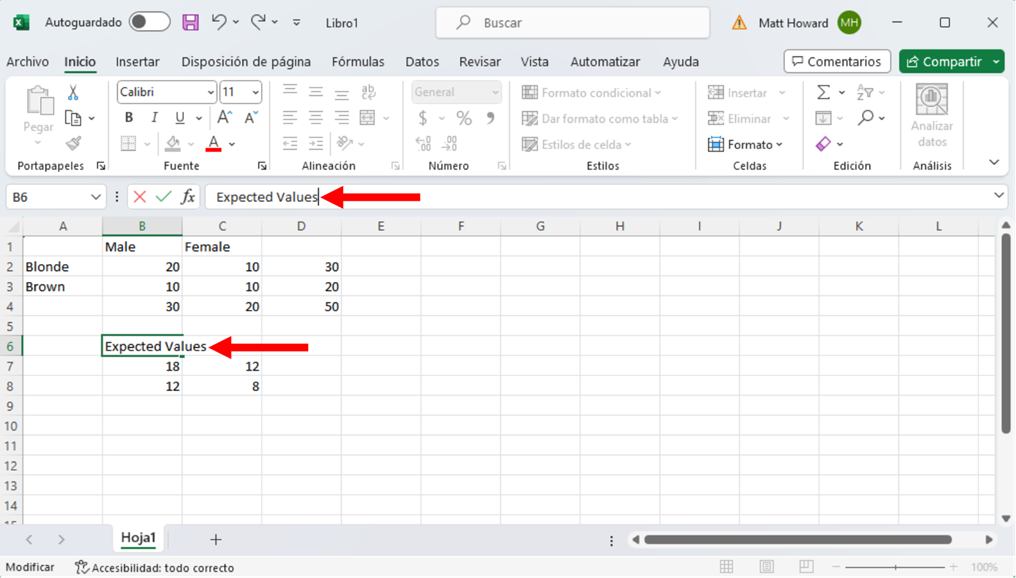
Ahora ya deberías tener los cuatro valores esperados y una etiqueta. ¡Buen trabajo!
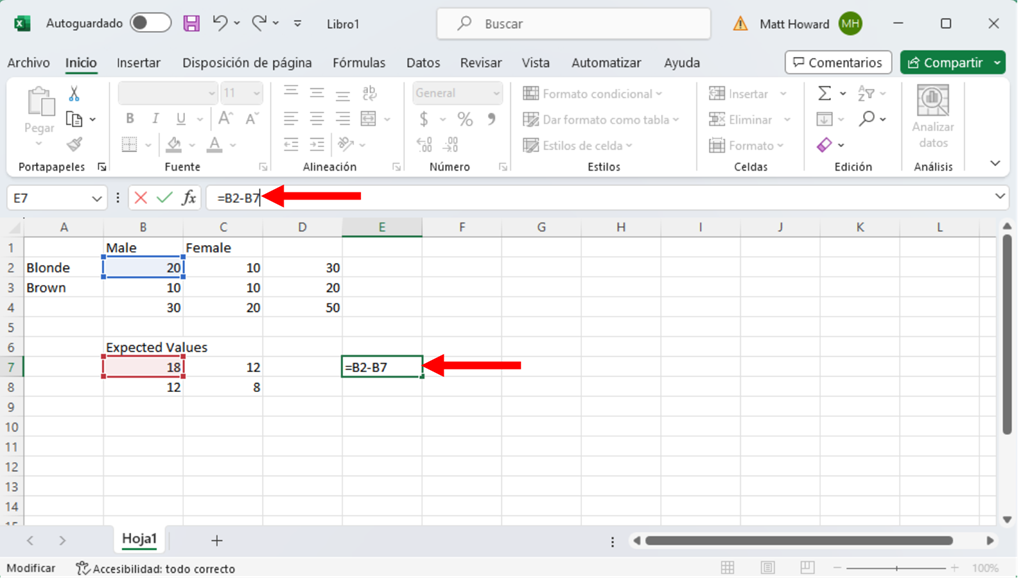
Ahora vamos a restar los valores originales observados por los valores esperados. Empecemos de nuevo con la celda superior izquierda. Primero selecciona una celda en blanco, como la resaltada abajo. Escribe “=”, selecciona el valor observado superior izquierdo, escribe “-“, selecciona el valor esperado superior izquierdo y pulsa intro.
Repitamos el proceso para las otras tres celdas y démosle una etiqueta a su nueva sección. Yo utilicé la etiqueta, “Obs-Exp”.
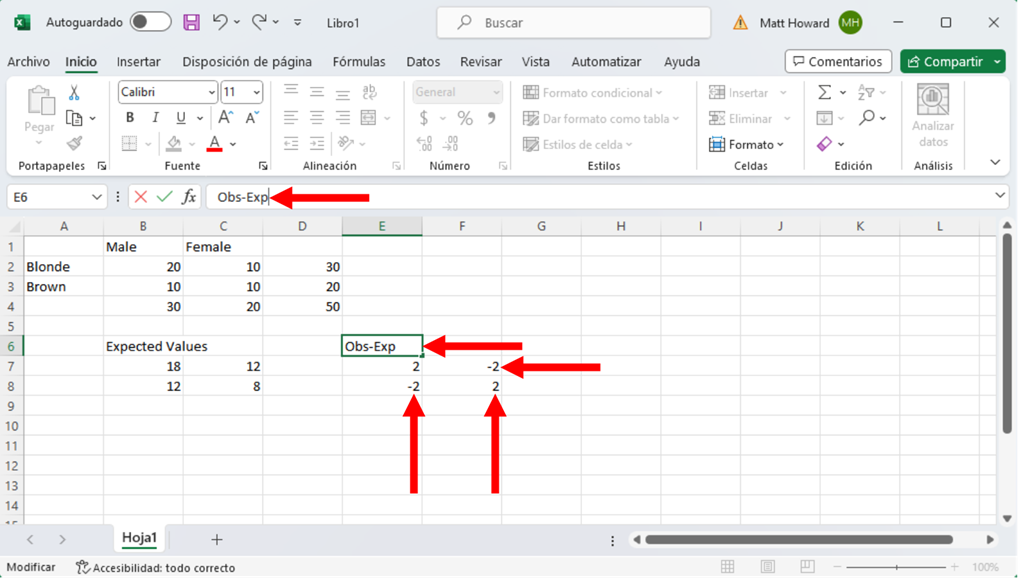
¿Se parecen tus valores observados menos los esperados a los de la imagen anterior? Si es así, ¡buen trabajo! Si no es así, vuelve atrás e inténtalo de nuevo.
Tenemos que cuadrar estos nuevos valores, empezando por la celda superior izquierda. De nuevo, selecciona una celda en blanco. Luego escribe “=”, selecciona la celda superior izquierda de los valores observados menos los esperados, escribe “^2”, y pulsa intro. Para escribir “^”, mantén pulsada la tecla Mayús y pulsa el número 6 del teclado.
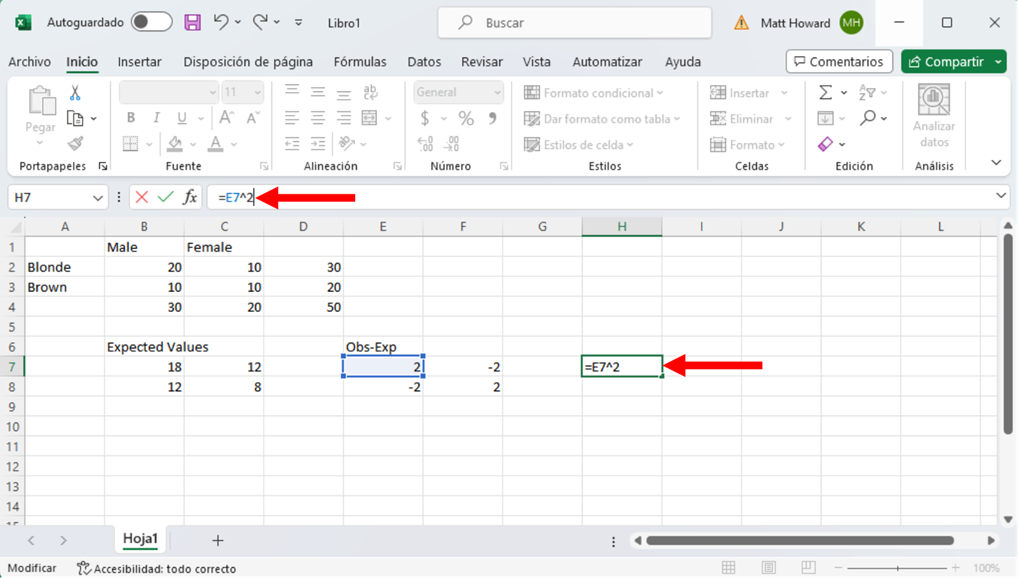
Repitamos el proceso para las otras tres celdas y añadamos una etiqueta. Yo he utilizado la etiqueta “Obs-Exp^2”.
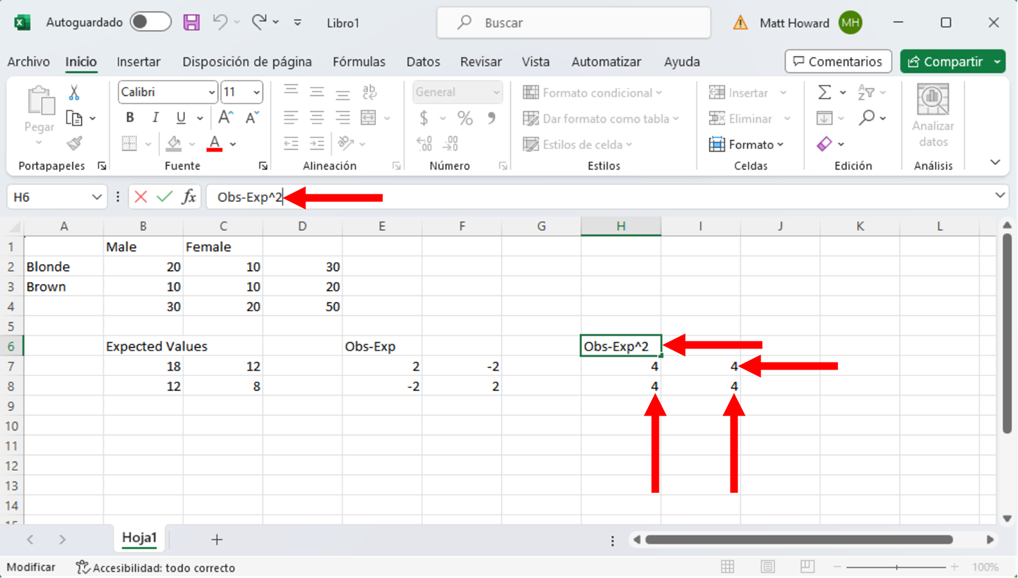
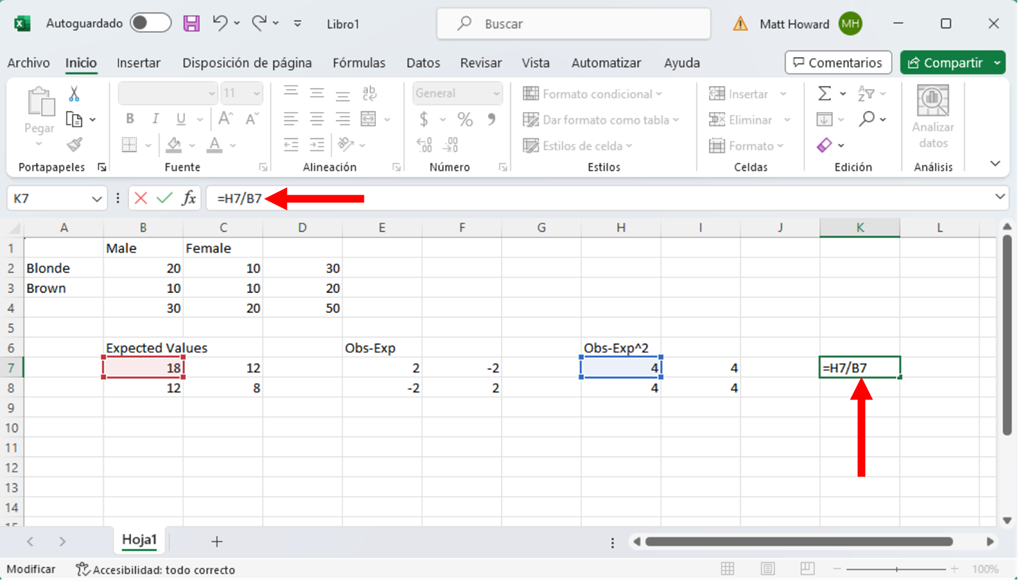
Ahora tenemos que dividir nuestros valores recién creados por nuestros valores esperados, empezando por la celda superior izquierda. Haz clic en una celda en blanco, escribe “=”. Selecciona la celda superior izquierda de los últimos valores creados, escribe type “/”, selecciona la celda superior izquierda de los valores esperados y pulsa Intro.
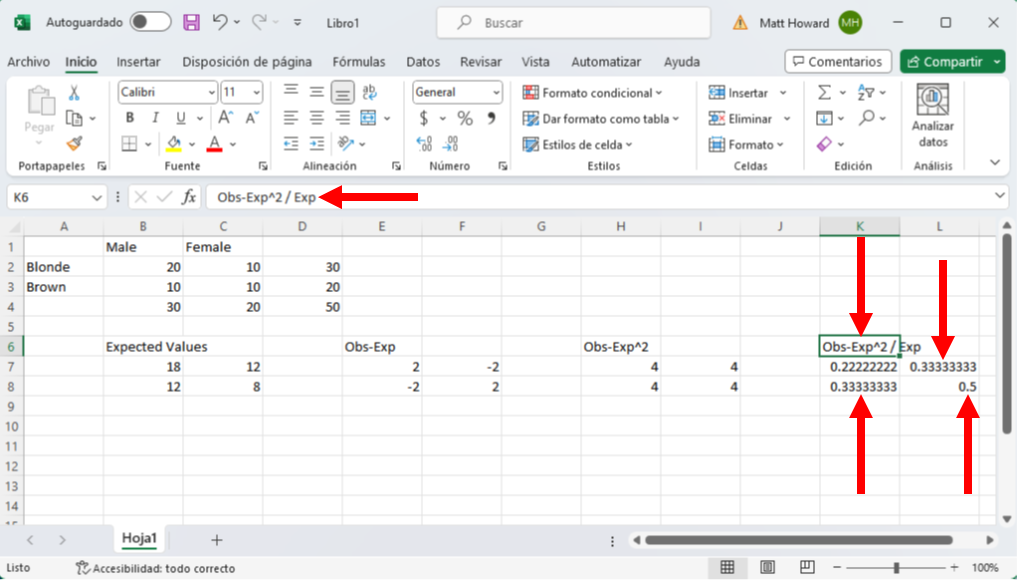
Una vez más, repite el proceso y añade una etiqueta. He utilizado la etiqueta “Obs-Exp^2 / Exp”.
Selecciona una celda en blanco, escribe “=SUMA(“, selecciona los cuatro valores recién creados, escribe “)”, y pulsa Intro.
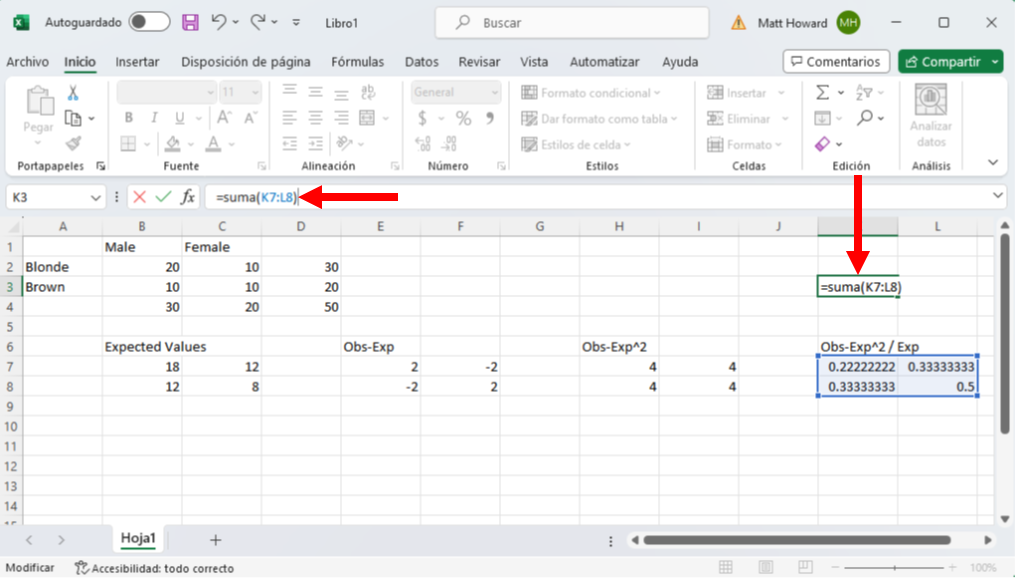
Finalmente, añade una etiqueta. Yo he etiquetado este valor final como, “Chi-Square Test Statistic” (Estadística de la Prueba Chi-Cuadrado).
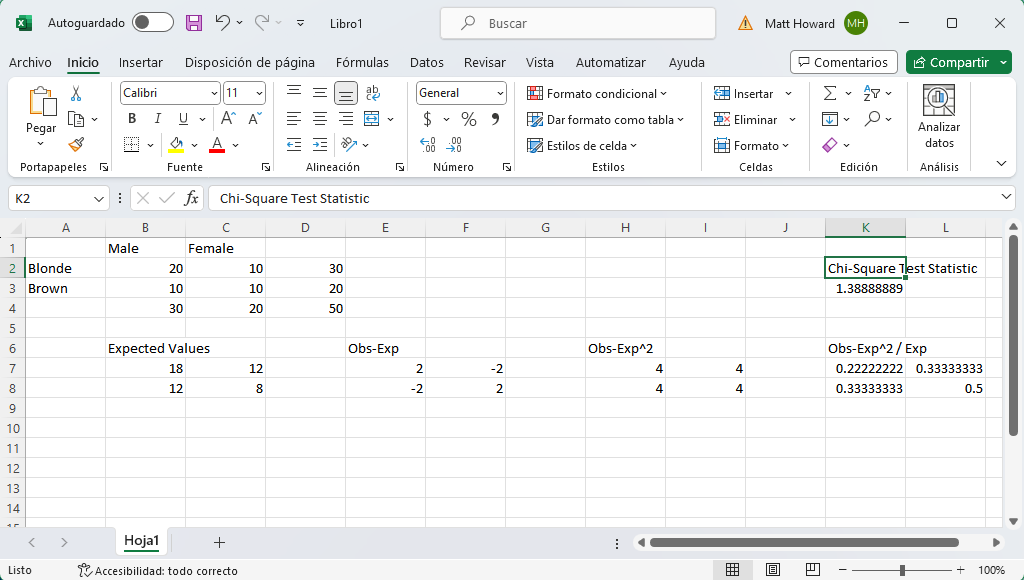
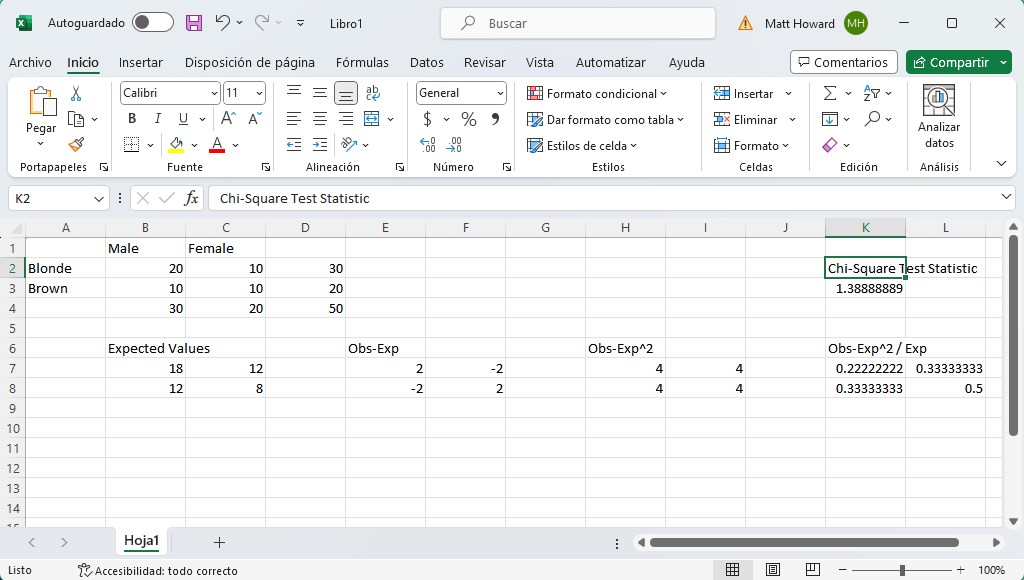
Ya hemos terminado con los cálculos. Observa la siguiente imagen. ¿Tus resultados se parecen a éste? ¿Has obtenido un valor final de 1.388889? ¡Estupendo! De nuevo, si no, mira las imágenes de arriba y comprueba en qué se diferencian tus números.
Entonces, ¿qué significa un estadístico de prueba chi-cuadrado de 1.38889? Para averiguarlo, tenemos que utilizar una tabla de significación chi-cuadrado. Para utilizar esta tabla (más abajo), tenemos que determinar nuestros grados de libertad, así como cuál queremos que sea nuestro nivel de significación (también conocido como alfa).
Para una prueba chi-cuadrado de independencia (dos variables), nuestro número de grados de libertad es el número de filas menos uno multiplicado por el número de columnas menos uno. Esto se expresa en la siguiente fórmula:
- df = (#r – 1)*(#c – 1)
En este ejemplo, introduciríamos el número dos tanto para el número de columnas como para el número de filas. Esto nos daría lo siguiente:
- df = (2 – 1)*(2 – 1)
- df = (1)*(1)
- df = 1
Así que nuestros grados de libertad son 1. ¿Qué pasa con nuestro alfa? Lo establecemos nosotros mismos, y casi siempre utilizamos un valor de 0.05. Esto se debe a que sólo consideramos un resultado estadísticamente significativo si el valor p es inferior a 0.05. Esto se debe a que sólo consideramos que un resultado es estadísticamente significativo si el valor p es inferior a 0.05.
Cuando estos números se deciden, utilizamos la tabla siguiente para encontrar nuestro valor de corte de la prueba chi-cuadrado. Si nuestro resultado es superior al número de la tabla, entonces nuestros resultados son estadísticamente significativos. Por lo tanto, en la imagen de abajo, encuentra donde la fila de un grado de libertad se cruza con la columna de .05 de nivel de significación.
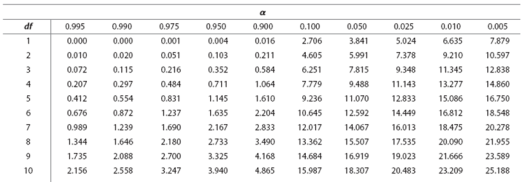
¿Lo encontraste? El número es 3.841. Por lo tanto, nuestro resultado debe ser mayor que 3.841 para ser estadísticamente significativo. Como nuestro resultado fue 1.388889, podemos decir con seguridad que no fue estadísticamente significativo. Esto significa que las dos variables pueden considerarse independientes en cuanto a la distribución de sus observaciones. El número de observaciones para el sexo no dependió del color del pelo, y el número de observaciones para el color del pelo no dependió del sexo. Las dos variables se consideran independientes.
Esto es todo sobre las pruebas de chi-cuadrado de una variable. Espero que esta página haya sido de ayuda. Si todavía tienes preguntas, ponte en contacto conmigo en MHoward@SouthAlabama.edu.
