
Por lo general, les digo a los estudiantes que las dos categorías principales de estadísticas “básicas” son si (a) determinan la relación entre cosas o si determinan (b) las diferencias entre grupos. A veces, sin embargo, se desea hacer ambas cosas. Para hacer esto, la regresión con variables dummy puede ayudar. Esta página es una breve lección sobre cómo realizar una regresión con variables dummy en Excel. ¡Como siempre, si tienen alguna pregunta, envíenme un email a MHoward@SouthAlabama.edu!
El tipo típico de regresión es una regresión lineal, la cual identifica una relación lineal entre predictor(es) y un resultado. Lo crean o no, una regresión lineal también puede identificar bastante bien las diferencias entre grupos – siempre que sepamos cómo codificar nuestros predictores correctamente. Aquí es donde puede entrar en juego la codificación simulada (dummy coding), que se puede usar para responder las siguientes preguntas y otras similares:
- ¿Cuál es la relación de los grupos de capacitación de las personas en su desempeño laboral teniendo en cuenta su satisfacción laboral?
- ¿Cuál es la relación del condado de residencia de las personas con su satisfacción con la vida al contabilizar sus ingresos?
- ¿Cuál es la relación del proceso de fabricación de un aparato con su calidad evaluada teniendo en cuenta la permanencia del operador de la máquina?
Por supuesto, hay más matices en la regresión con variables dummy, pero lo mantendremos simple. Para responder a estas preguntas, podemos usar Excel para calcular una ecuación de regresión. Si no tienen un conjunto de datos, pueden descargar el conjunto de datos de ejemplo aquí. En este conjunto de datos, estamos investigando las relaciones de tres grupos de capacitación y concientización con las ventas.
Los datos deberían verse como esto:
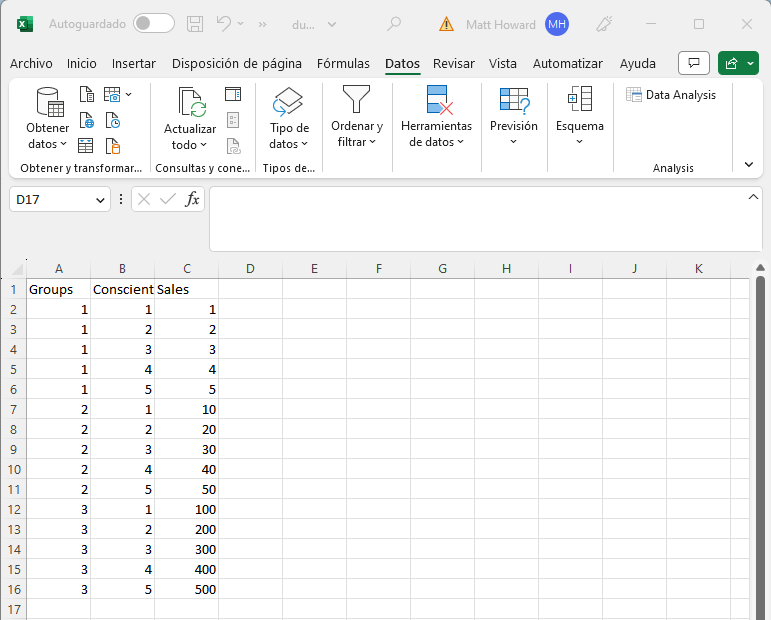
Si su conjunto de datos se ve diferente, deben intentar reformatearlo para que se parezca a la imagen de arriba. Las instrucciones a continuación pueden ser un poco confusas si los datos se ven un poco diferentes.
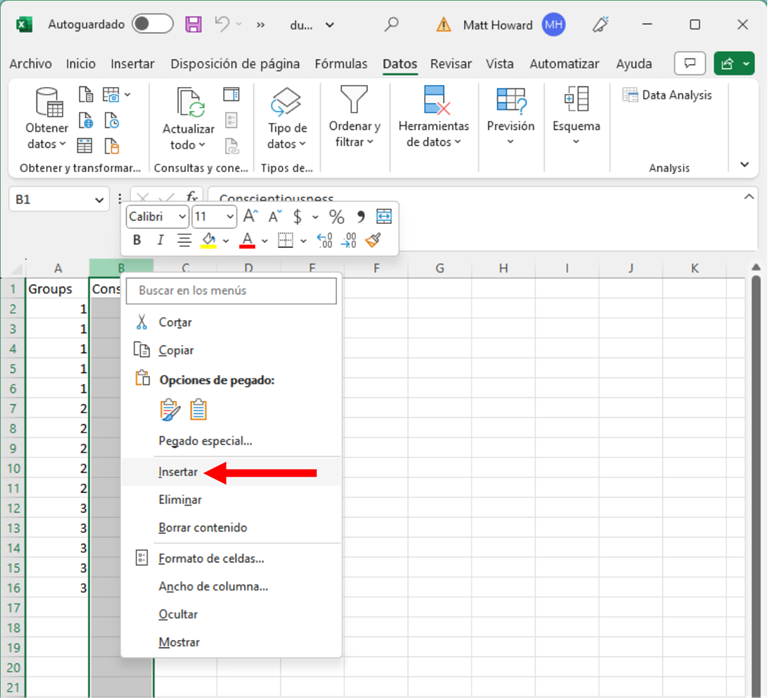
Para realizar una regresión con variables dummy, primero debemos crear una nueva variable para la cantidad de grupos que tenemos menos uno. En este caso, haremos un total de dos nuevas variables (3 grupos – 1 = 2). Para hacerlo en Excel, primero debemos hacer clic con el botón derecho en nuestra columna de resultados y luego hacer clic en Insertar. Y entonces hagan esto de nuevo.
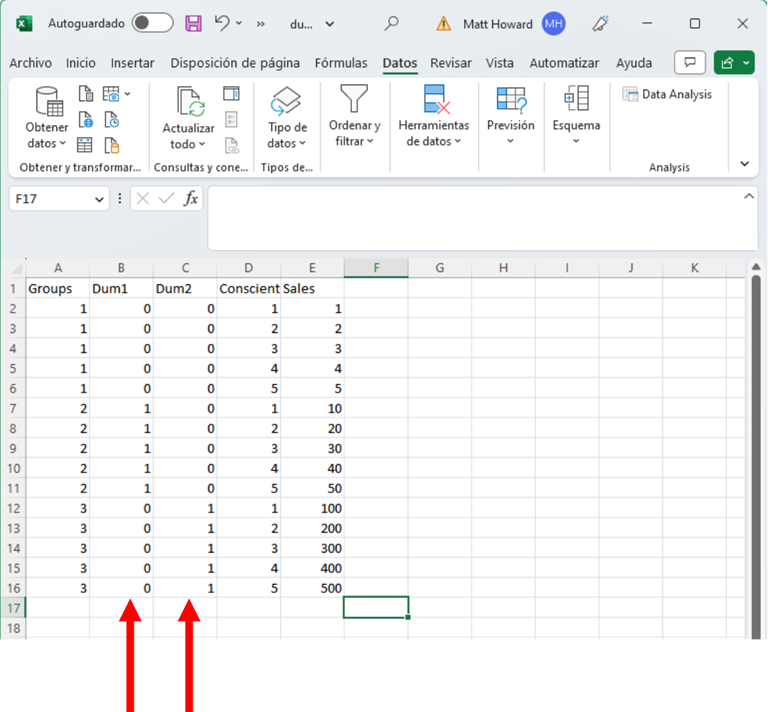
Esto debería crear dos nuevas columnas. En la primera columna nueva, querrán que cada persona del Grupo 2 tenga un 1 para su valor, y que cada una de las demás personas tenga un 0. En la segunda columna nueva, querrán que cada persona del Grupo 3 tenga un 1 para su valor, y todos los demás tengan 0. Al realizar estos análisis, tendrán el Grupo 1 como el “grupo de referencia” con el que se comparan los Grupos 2 y 3. Si lo hacen correctamente, su conjunto de datos debería verse como la siguiente imagen:
Una vez que tengamos los variables dummy correctos, realizaremos una regresión como de costumbre. Hagan clic en Data Analysis. ¿No ve esa pestaña? Si no es así, vaya a mi página sobre Activación de la pestaña Data Analysis. Debería aparecer una vez que la active.
Entonces Regresión y Aceptar.
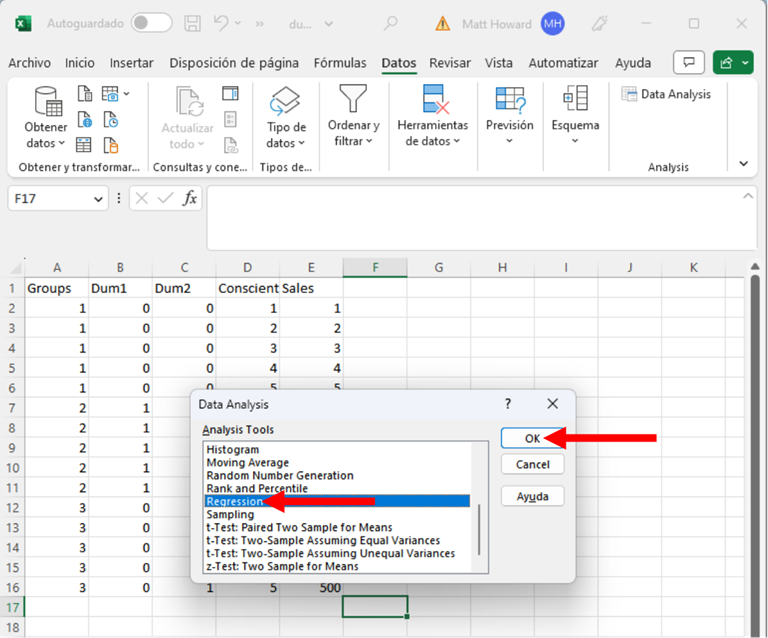
Luego, hagan clic en el botón a continuación para identificar los datos de resultado (su Y Range).
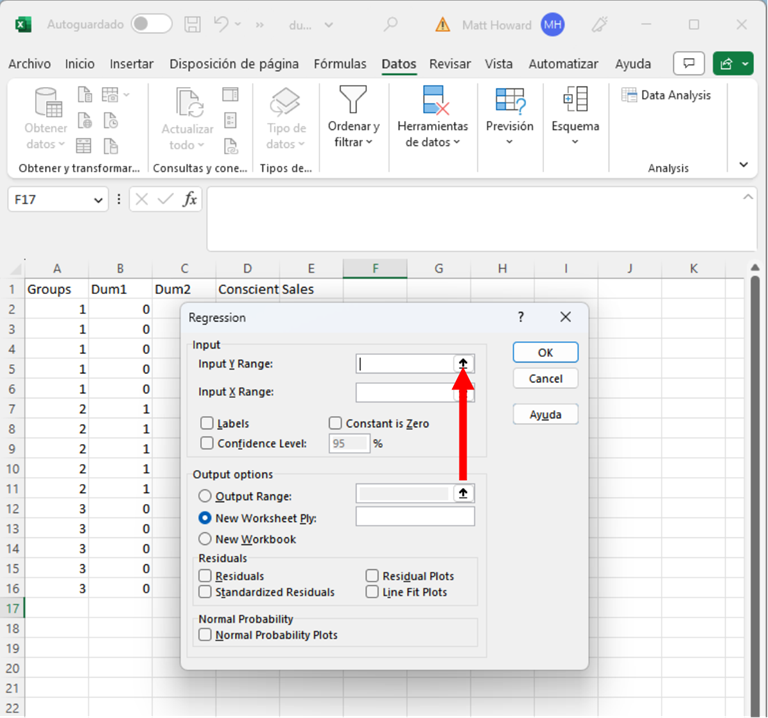
Resalten los datos de resultado, incluida la etiqueta. Luego hagan clic en el botón que se muestra a continuación.
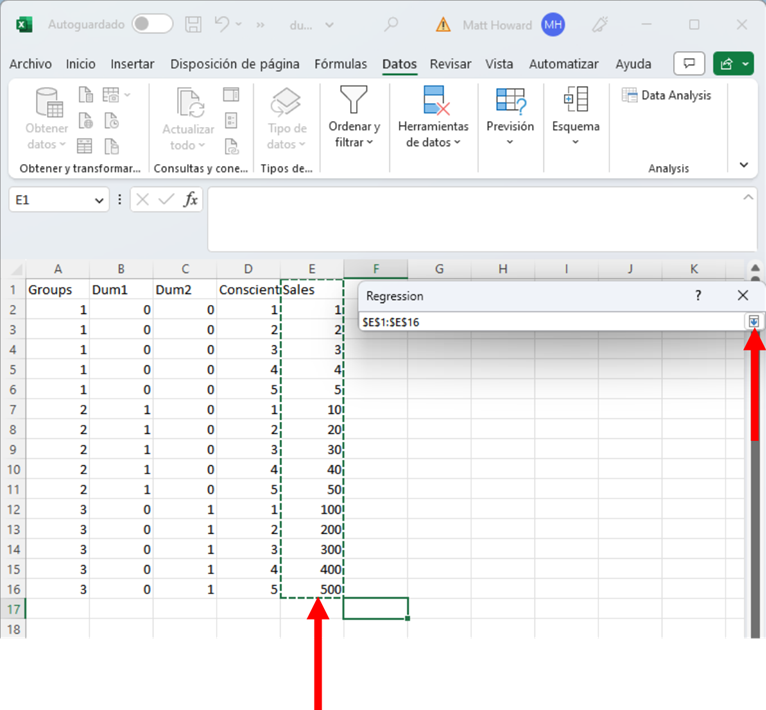
Ahora, hagan clic en el botón de abajo para identificar los datos predictores (su X Range).
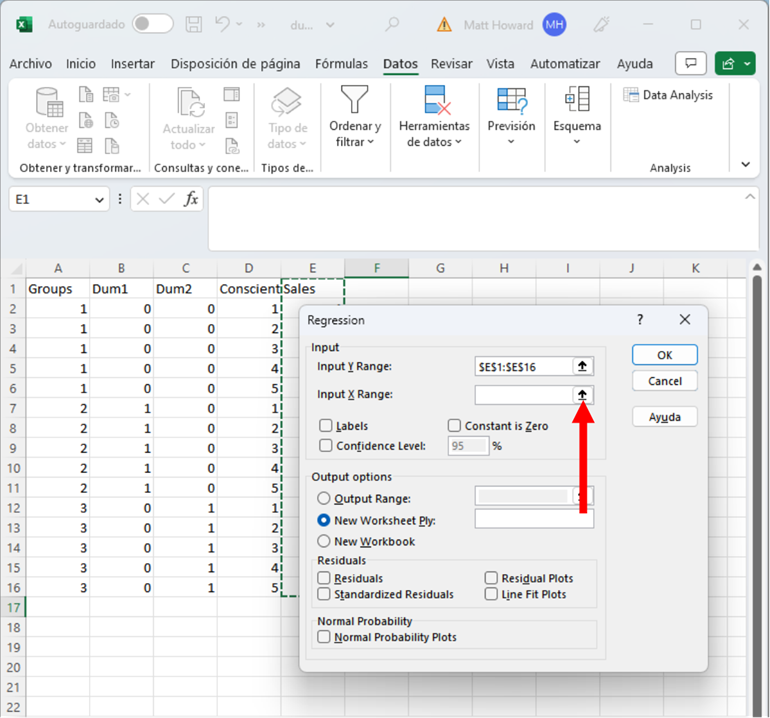
Ahora, resalten AMBAS variables dummy y la otra variable predictora, incluidas las etiquetas. Luego hagan clic en el botón que se muestra a continuación.
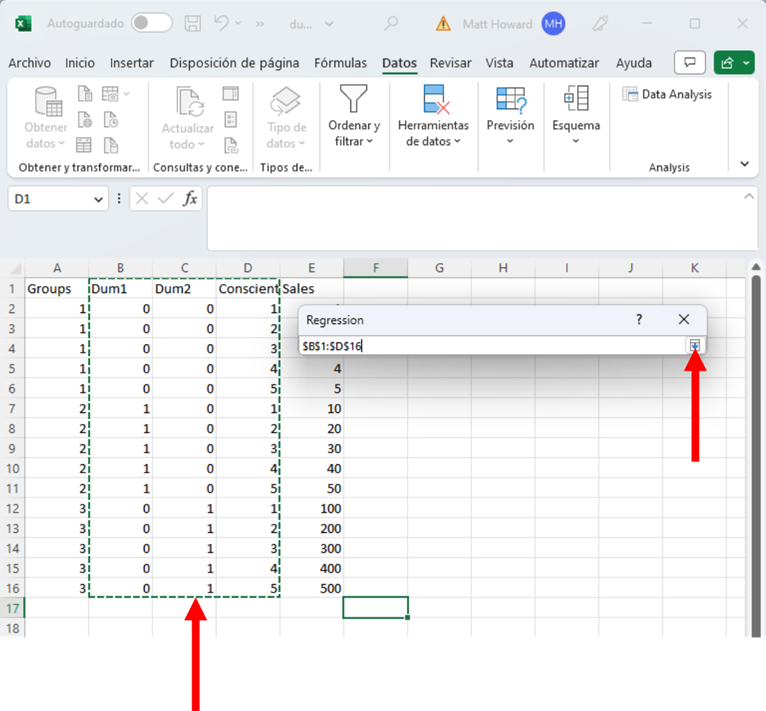
Por último, haga clic en el cuadro de Labels y presionen Aceptar.
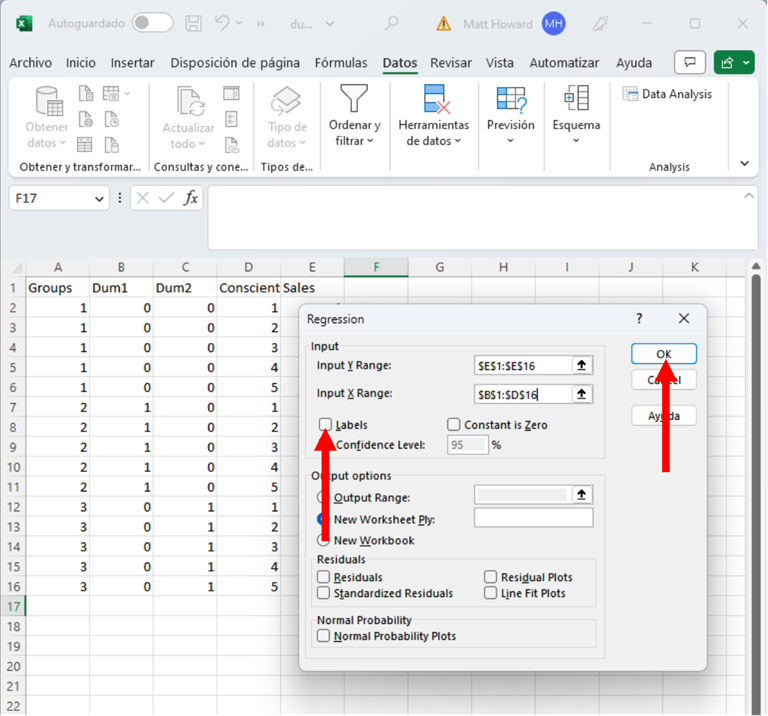
¡Deberíamos obtener los resultados! ¡Hurra!
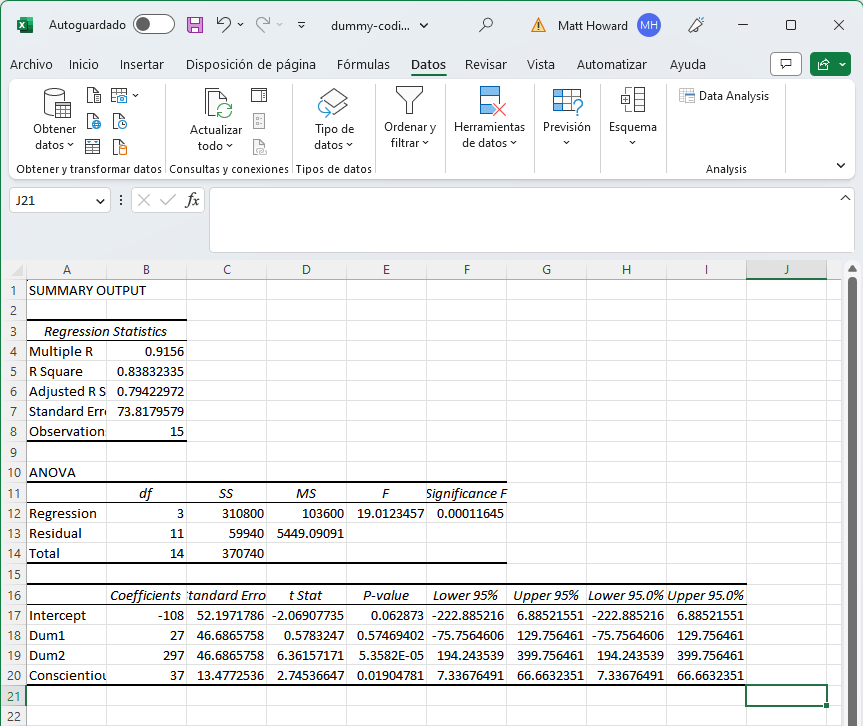
Si necesitan ayuda para leer esta tabla, consulten mi guía Regresión en Excel. De lo contrario, podemos ver claramente que la beta no estandarizada para el Variables Dummy 1 es 27; la beta no estandarizada para el Variables Dummy 2 es 297 y la beta no estandarizada para la concientización es 37. El Variables Dummy 1 no es estadísticamente significativo (p > 0.05), lo que sugiere que no hubo una diferencia significativa entre los Grupos 1 y 2. El Variables Dummy 2 fue estadísticamente significativo (p < 0.001), lo que sugiere que hubo una diferencia significativa entre los Grupos 1 y 3. El efecto de la concientización fue significativo (p < 0.05), lo que sugiere que este predictor tuvo una influencia significativa en las ventas. Por último, el coeficiente de determinación (R-Square) general es 0.84, ¡lo cual es muy alto para las ciencias sociales!
Por supuesto, los resultados brindan otra información, la cual puede ser útil para ciertos propósitos, pero la guía actual sólo cubre los aspectos básicos.
Además, debe tenerse en cuenta que se pueden realizar otros tipos de codificación para comparar grupos a través de la regresión, como effects coded variables. Entonces, si ven que alguien usa números de codificación diferentes a 0 y 1, ¡no asuman que están equivocados!
Ahora ya deberían poder realizar una regresión con variables dummy en Excel. ¡Como siempre, si tienen alguna pregunta o comentario, envíeme un email a MHoward@SouthAlabama.edu!
