
T-tests are used to identify the mean difference between two groups. But what do you do if you want to compare the mean difference of more than two groups? Well, as you’ve probably guessed, you can perform an ANOVA. Because ANOVA is a commonly-used statistical tool, I created the page below to provide a step-by-step guide to calculating an ANOVA in R. This page is for a one-way ANOVA, which is when you have a single grouping variable and a continuous outcome. As always, if you have any questions, please email me a MHoward@SouthAlabama.edu!
As mentioned, an ANOVA is used to identify the mean difference between more than two groups, and a one-way ANOVA is used to identify the mean difference between more than two groups when you have a single grouping variable and a continuous outcome. So, a one-way ANOVA is used to answer questions that are similar to the following:
- What is the mean difference of test grades between Dr. Howard’s class, Dr. Smith’s class, and Dr. Kim’s class?
- What is the mean difference in total output of five different factories?
- What is the mean difference in performance of four different training groups?
Now that we know what an one-way ANOVA is used for, we can now calculate an one-way ANOVA in R. To begin, open your data in R. If you don’t have a dataset, download the example dataset here. In the example dataset, we are simply comparing the means of three different groups on a single continuous outcome. You can imagine that the groups and the outcome are anything that you want.
Also, this dataset is in the .xlsx format, and the current guide requires the file to be in .csv format. For this reason, you must convert this file from .xlsx format to .csv format before you can follow along using this dataset. If you do not know how to do this, please visit my page on converting a file to .csv format. After converting the file, you can continue with this guide.
First, you must import your data to R. For the current examples, we are going to label our data as: MyData. For a more in-depth review of opening data in R, please visit my guide on the topic.
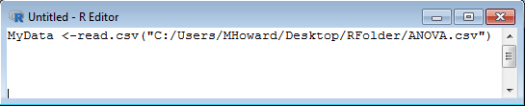
Before conducting our ANOVA, we need to first indicate that our grouping variable within our dataset is indeed a grouping variable. To do this, we first refer to our grouping variable in our dataset, which is MyData$Groups, followed by an arrow, <- . So, we would type MyData$Groups <- .
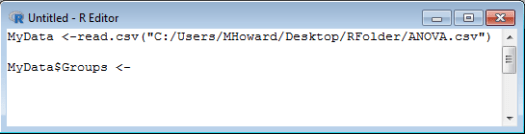
Now, we use the command as.factor() to indicate that our grouping variable is a grouping variable. Type: as.factor( .
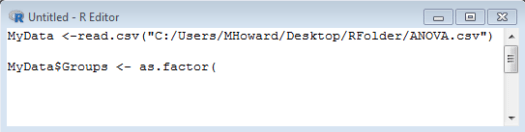
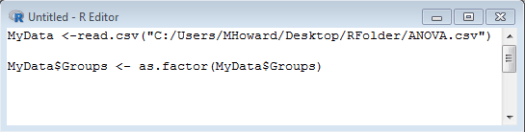
Finally, type your grouping variable again and close your bracket by typing: MyData$Groups) .
We are going to assign our output to the following term: fit . So, please type: fit <- .
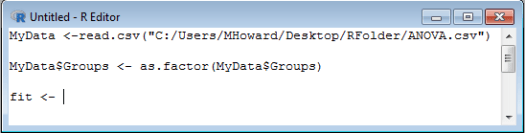
For our analysis, we are going to use the aov() command. Type: aov( .
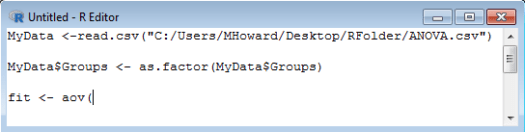
In the aov() command, the first variable that we enter is our outcome variable. For our dataset, out outcome variable is labeled Outcome. We also need to identify that this is our outcome variable within the command by typing a ~. So, we would type: Outcome ~ .
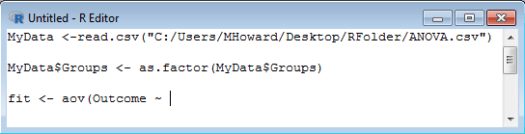
Next, we identify our grouping variable. In the current dataset, our grouping variable is labeled Groups. We should thereby type: Groups, .
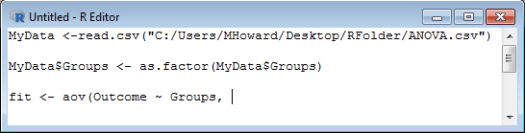
Now, we just need to identify our dataset and close our command. Type: data=MyData).
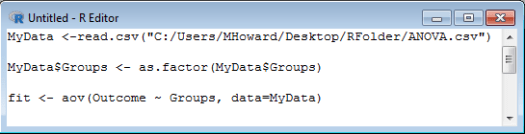
Because we are assigning our output to “fit,” we need to tell R to provide a summary of fit. On the following line, we should therefore type: summary(fit) .
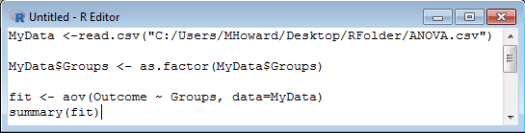
Run your syntax to get your output. . .
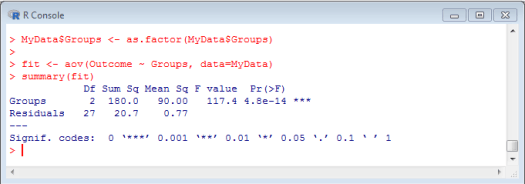
Did you get these results? Great! From these results, we can see that our test statistic, the F-value, is 117.4. We can also see that our p-value is extremely small, with a value of 4.8e-14. In non-scientific notation, this is .000000000000048. Likewise, our results are highlighted with ***, which indicates that our p-value is less than .001. So, clearly, our results are statistically significant, and there is a difference among our groups.
But what type of difference is there among our groups? To figure this out, we will need to perform a post hoc test. Post hoc tests compare each of the groups to determine the group differences, and many different types of post hoc tests exist. Likely the easiest to perform in R is the TukeyHSD post hoc test. So, type: TukeyHSD(fit) .
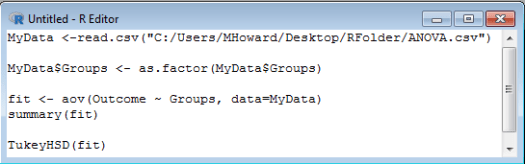
And then run this additional line of syntax.
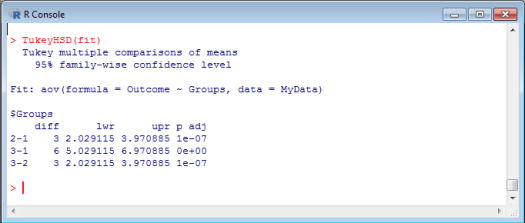
These results represent each group comparison. As you can see, the first line represents the difference between groups 2 and 1 (difference of 3), the second line represents the difference between groups 3 and 1 (difference of 6), and the final line represents the difference between groups 3 and 2 (difference of 3). As apparent from the p-values, each comparison was statistically significant. The first (2 and 1) and last (3 and 2) comparisons had p-values of .0000001. The middle (3 and 1) comparison had a p-value that rounded to zero in our output. Each of these are well below .05. Therefore, we would say that our overall ANOVA result is statistically significant, and each individual group comparison is also statistically significant.
That is all for one-way ANOVAs in R! If you have any questions, please email me at MHoward@SouthAlabama.edu. I am always happy to help!
