
In most of my undergraduate statistics courses, I begin with a lesson on
Independent Variables (IV) and Dependent Variables (DV). Identifying the IV and DV is essential to understanding most statistical procedures (i.e. correlation, t-test, regression, etc.), which makes the topic extremely important to master. For this reason, this page is a little blurb on the topic.
There are many ways to describe IVs and DVs. Below are four different ways:
1.) The IV is the predictor whereas the DV is the outcome.
2.) The IV is “something” that leads to “something else,” and the “something else” is the DV.
3.) The IV causes the DV.
4.) The IV isn’t changed by other variables, whereas the DV is changed by other variables.
Do you understand the difference between IV and DV? Let’s take the following
hypotheses to help clarify things. Read each hypothesis and try to identify the IV and the DV. Then, the answer will follow the hypothesis.
1.) Watching violent TV causes aggression.
1a.) Watching violent TV is the IV, and aggression is the DV.
2.) Bad posture causes back pain.
2a.) Posture is the IV, and back pain is the DV.
3.) Boys watch more violent TV than girls.
3a.) Gender is the IV, and watching violent TV is the DV.
4.) Aggression is caused by watching violent TV.
4a.) Watching violent TV is the IV, and aggression is the DV.
Did you get these examples correct? More importantly, did you understand the examples? If so, great! If not, let’s look at the pictures below. For each picture, try to guess which circles are the IVs and which circles are the DVs.
1.) 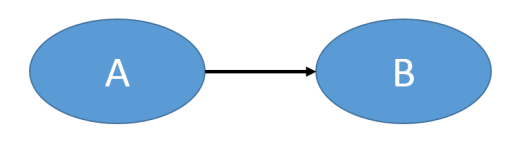
1a.) A is the IV, whereas B is the DV.
2.) 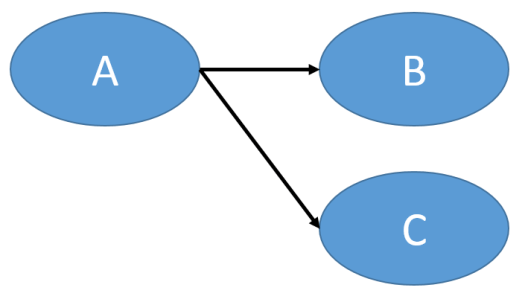
2a.) A is the IV, whereas B and C are the DVs.
3.) 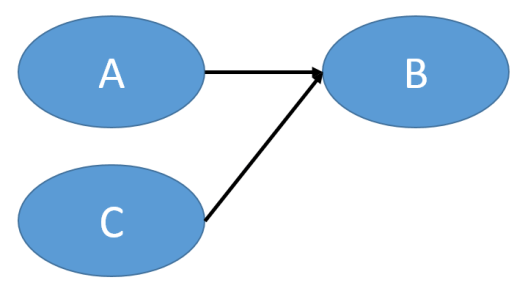
3a.) A and C are the IVs, whereas B is the DV.
Did you get those correct? Examples 2 and 3 might have been a little confusing. Most often, we do not include multiple relationships in our hypotheses, so you will not have multiple IVs and DVs in a single hypothesis; however, you can join
multiple hypotheses to make a model similar to Examples 2 and 3. For example, the hypotheses that make the model in Example 3 might look like:
Hypothesis 1: A causes B.
Hypothesis 2: C causes B.
In the first hypothesis, A is the IV and B is the DV. In the second hypothesis, C is the IV and B is the DV. So, when we combine these hypotheses, we get the model in Example 3. Sorta neat, right?
Lastly, a quick note should be made about experimental studies. Usually when we perform experiments, we manipulate one variable to determine its impact on the other. For example, we may have two groups of participants. In group A, the participants are given free cookies. In group B, the participants are given broccoli. Then, both groups take a test, and we observe whether the given food has an
impact on test grades. For experimental studies, the IV is the variable that we manipulate, and the DV is the variable impacted by the IV. In the current example, the IV would be the food given, and the DV would be the test scores. Remember, this only applies to experimental studies. In correlational studies, we do not
manipulate anything, but we would still likely have IVs and DVs.
Well, that is my crash-course on IVs and DVs. Do you have any questions? If so, please email me at mch248@psu.edu . I’d be happy to provide more information!
